近年では主にビジネス面で、音声認識モデルが注目を集めています。
これにより、議事録を文字起こしする、インタビュー内容を要約するなどできるようになりました。実際にこのテクノロジーに興味を持っている人も多いでしょう。
そんな中、OpenAIから音声認識モデルのWhisperがリリースされました。しかし、
- Whisperでは何ができるのか
- 費用はどのくらいかかるのか
- どのように操作するのか
といった疑問を持っている人は多いでしょう。Whisperは比較的新しいツールであり、まだ情報が出揃っていないのが実情です。
そこで本記事では、Whisperの基礎情報や利用料金、使い方を解説。導入を考えている方はぜひ参考にしてください。
Whisperとは?概要・音声認識モデル・メリットを解説

Whisperは、大量の音声データを学習させた音声認識モデルのひとつです。
このモデル自体はかねてから存在しましたが、昨今のAIブームの発端となったOpenAIが開発したことから、より多くの注目を集めています。
Whisperは68万時間分の音声データを学習済み。このデータを活用し、人の声をきわめて高い精度で聞き分け、指示を理解する、文字起こしするなどできます。
WhisperとGPTで「会話を聞きながら誤りをひたすら指摘するロボ」が出来た。
— Ken Kawamoto(ガリのほう)_1 (@kenkawakenkenke) April 10, 2023
僕「Appleが作ったGPTは…」GPT「GPTを作ったのはOpenAIです」
みたいに勝手に割り込んできて直してくれる。(なお英語のみ)
これはかなりイラつくんだけど、会話に勝手に入ってくる系AIは色々便利なものが作れそう。 pic.twitter.com/bbXowaBp6z
設定を突き詰めると、このように「会話を聞きながら、間違いがあれば是正してくれる」といった機能を持たせることが可能です。
他にも設定しだいではさまざまな形で貢献できる(後述)ので、非常に使い勝手がよいと言えるでしょう。
続いてWhisperの、プロダクトの基本情報として以下を解説します。
- 基本的な機能
- Whisperの利用料金
- モデル一覧
- 利用するメリットとデメリット
それぞれ詳しく解説するので参考にしてください。
基本的にできること
Whisperを導入した場合、一般的に以下のようなことができるようになります。
- 音声ファイルの認識・書き起こし
- 音声データの翻訳
- 指示を理解
- 家電操作
- 議事録の自動作成
- 本人認証
- 機器の遠隔操作
- 音声型チャットボットの構築
- YouTube動画の音声取得
基本的には書き起こし、翻訳、議事録の自動作成などは実現しやすいようです。これができるだけでも、相当なリソース・コストの削減などにつながるでしょう。
またその精度も十分です。こちらの動画の9:15~あたりから、その精度の高さがうかがい知れます。
そのほかにも設定しだいでは、さまざまな操作ができるようになります。Whisperの扱いに慣れてきたら、機能の拡張にチャレンジしてみるのもよいでしょう。
Whisperの利用料金
Whisperの利用料金は、1分あたり0.006ドルと定められています。

日本円に換算すると、1分あたり0.93円。1時間の音声を扱ったのなら、55.8円かかる計算です。
ただし後述するGoogle Colaboratory版Whisperなら費用はかかりません。そちらの導入方法は後ほど解説します。
モデル一覧
Whisperには以下5つのモデルが用意されています。このモデルの違いにより、スペックが異なります。
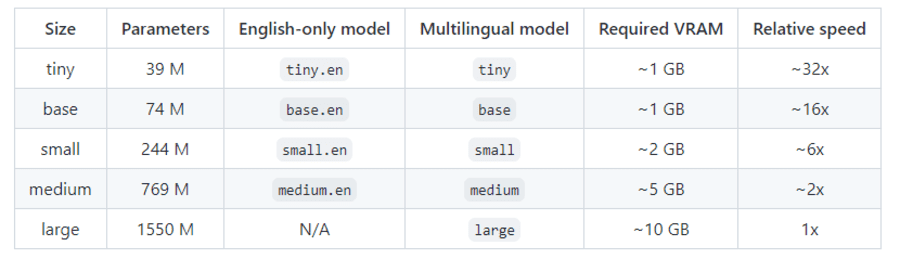
5つのモデルのうち「tiny」がもっとも高速で「large」がもっとも高性能です。ただしあくまでもモード設定であり、すべて利用料金は同一です。
特に重要なのはRelative speed。tinyなら、Largeと比較して最大32倍の速度でアウトプットします。
ただRelative speedは音声認識精度とトレードオフ。つまりLargeは時間がかかるものの、もっとも正確に音声認識できます。
English-only modelとMultingual modelに関しては、現時点でさほど差異がなく、あまり気にする必要はありません。
処理速度が必要なときはtiny、正確性が求められるときはlargeを使う、といった形で使い分ければ、まず問題はありません。
利用するメリット3つ

Whisperを利用するメリットは大きく分けて3つあります。
- 日本語を高精度で認識できる
- 料金が安く設定されている
- 幅広いファイル形式と言語に対応できる
1.日本語を高精度で認識できる
1つは、日本語の音声認識精度が極めて高いこと。
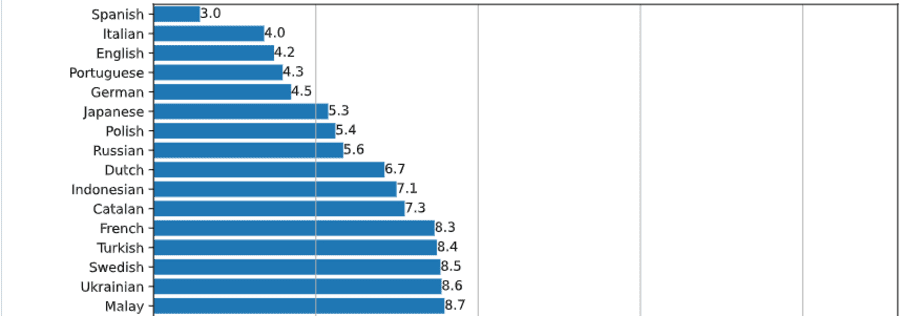
これは、Whisperの音声認識能力の誤認識率を言語別で分析したものです。Japaneseは全世界で6番目の精度で認識されます。全体の5.3%でしか誤認識が生じません。
2.料金が安く設定されている
また料金が安いのもメリットです。一般的な音声認識ツールは、月額で数万円かかることもあります。
しかしWhisperなら、たとえば100時間分の音声認識を実施しても、5,500円ほどの費用しかかかりません。
また1分単位での都度課金なので、無駄な月額料金を払うのも避けられます。
ただし企業単位で利用する場合は、つもり重なってまとまった出費になることも。無駄遣いしないように社内ルールをきちんと制定する必要がありそうです。
3.幅広いファイル形式と言語に対応できる
Whisperは、以下のような多様なファイル形式から音声を認識することが可能です。
- mp4
- mp3
- mpeg
- wav
- mpga
- webm
- m4a
これだけのファイル形式に対応しているなら、基本的に「読み込んでくれない」といった場面に出くわすことはないでしょう。
またITメディアのMediumによれば、Whisperは99の言語に対応しているとのことです。
マイナーな言語の翻訳などにも活用できるわけですね。
このように使い勝手がよく、対応力にも秀でているのが、Whisperの魅力だといえるでしょう。
デメリットはセキュリティ面の不安定感
ただしWhisperにもデメリットがあります。セキュリティ面で、一定の不安感があるという点です。
Whisperを利用するには、何らかの音声データをアップロードする必要があります。そしてそのデータはAIの自動学習に組み込まれ、削除などはできません。
そうすると自動学習をとおして、自社の重要なデータが別のユーザーにアウトプットされてしまうかもしれません。
なお同じくOpen AIのプロダクトであるChat GPTでは個人情報漏洩のインシデントがありました。
同じくOpen AI製のWhisperにも共通のリスクがあると考えられます。この点を踏まえて、Whisperを使うか、使うとしたらどう安全を確保するか考えるのが重要です。
Whisperを導入・インストールする方法
Whisperを導入・インストールする場合は、Google Colaboratoryを利用するのがおすすめです。
Googleが提供しているインストール不要のPythonプログラミング環境。Pythonを使えるのであれば、誰でもGoogle Colaboratory上でコーディングやその実行、もしくはシェアリングができる。
Google ColaboratoryやPythonが何を指すかよくわからない場合、Whisperを導入するのはすこし難しいかもしれません。
以下でそれぞれがどういうものか簡単に解説しているので参考にしてください。
Google Colaboratory▶︎【初学者必読】Google Colaboratory とは?使い方・便利な設定などをわかりやすく解説!
Python▶︎Pythonとは?特徴やできること、活用例をわかりやすく簡単に解説
これに関して理解できている方は、そのまま以下の手順に進みます。
- Google Colaboratoryを開く
- 新規ノートブックを作る
- Whisperをインストールする
- コードを追加する
- Whisperを導入する
それぞれ詳しく解説するので参考にしてください。
GitHub版と異なり、Google Colaboratory版は無料なので、基本的にはこちらを利用するのがおすすめです。
Google Colaboratoryを開く
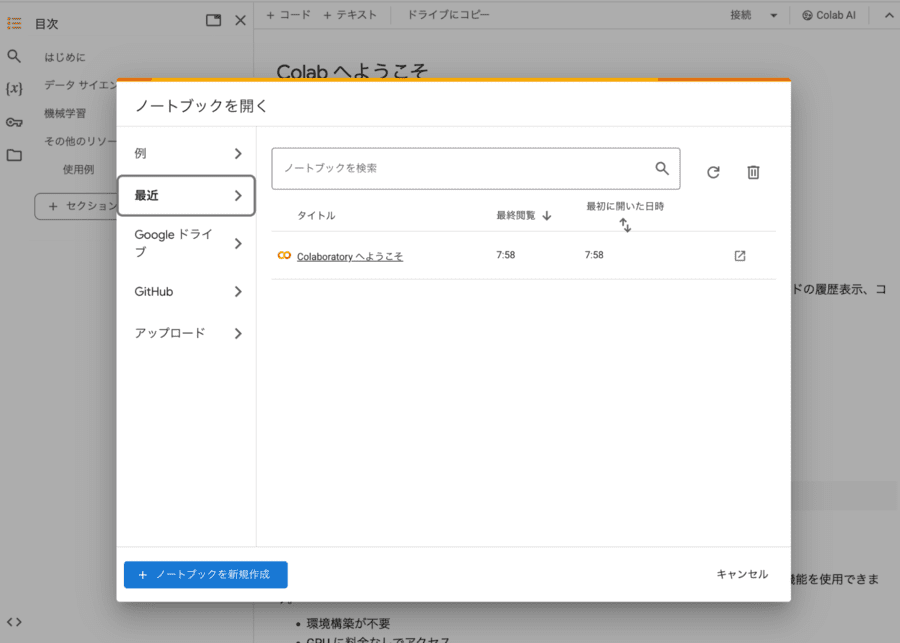
新規ノートブックを作る
続いてGoogle Colaboratoryで新規ノートブックを作成しましょう。これはWhisperの置き場所を作るようなイメージの作業です。
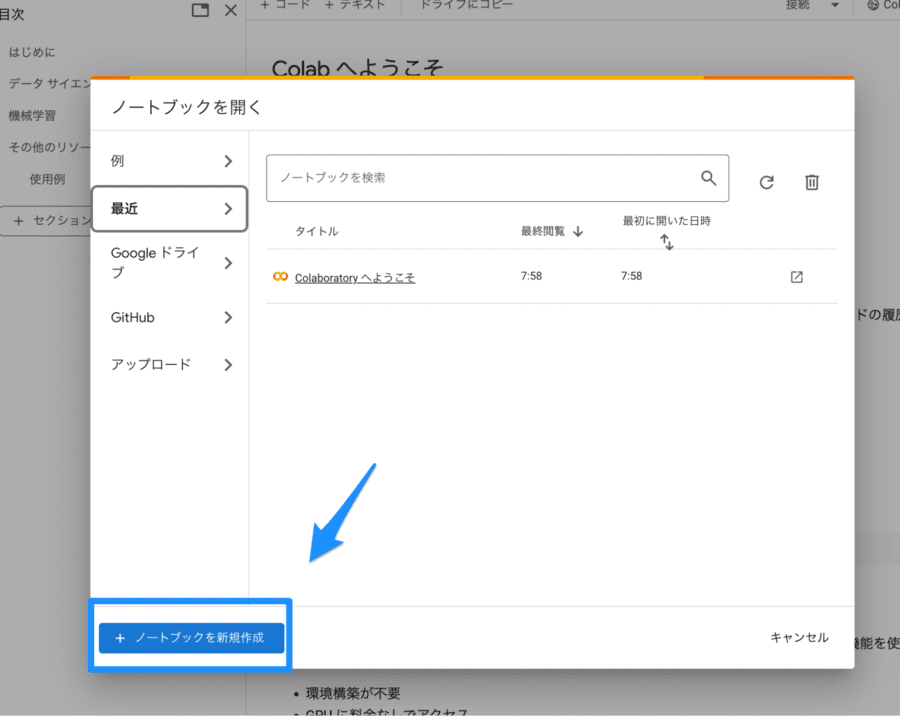
Google Colaboratoryのトップに表示されるポップアップウィンドウの左下、「ノートブックを新規作成」をクリックしましょう。
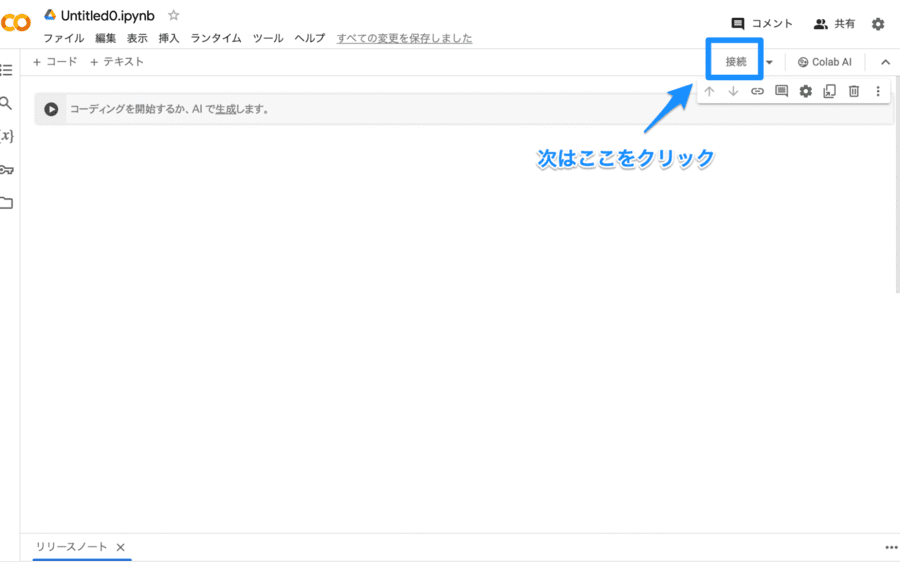
このようなコーディング画面が表示されます。確認できたら、画面右上の接続をクリックしましょう。これが、接続済みとなり、RAMという表示が出るまで待機します。
Whisperをインストールする
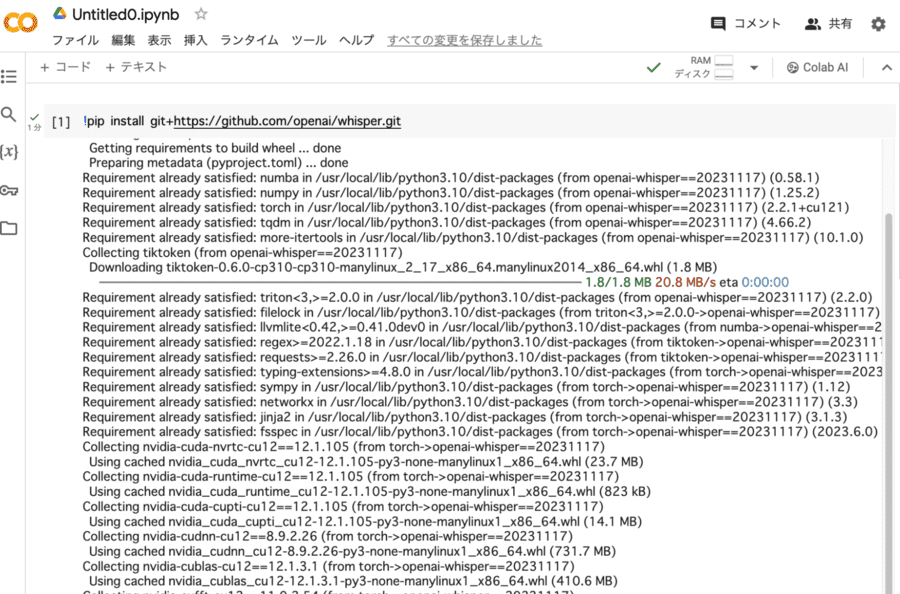
続いてコーディング用のテキストボックスに導入コードを入力します。
以下のコードをコピーしてペーストとしてください。
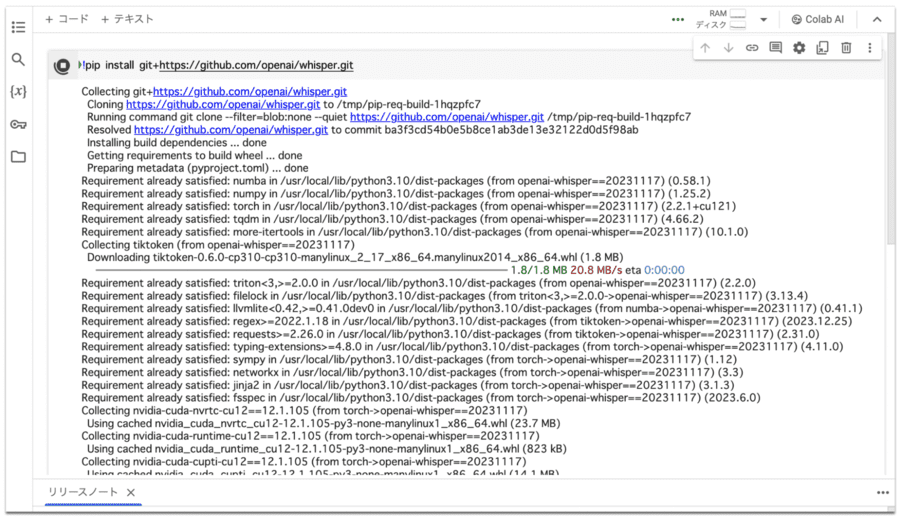
「!pip install git+https://github.com/openai/whisper.git」
入力できたら、テキストボックス左側にある再生ボタンをクリックします。
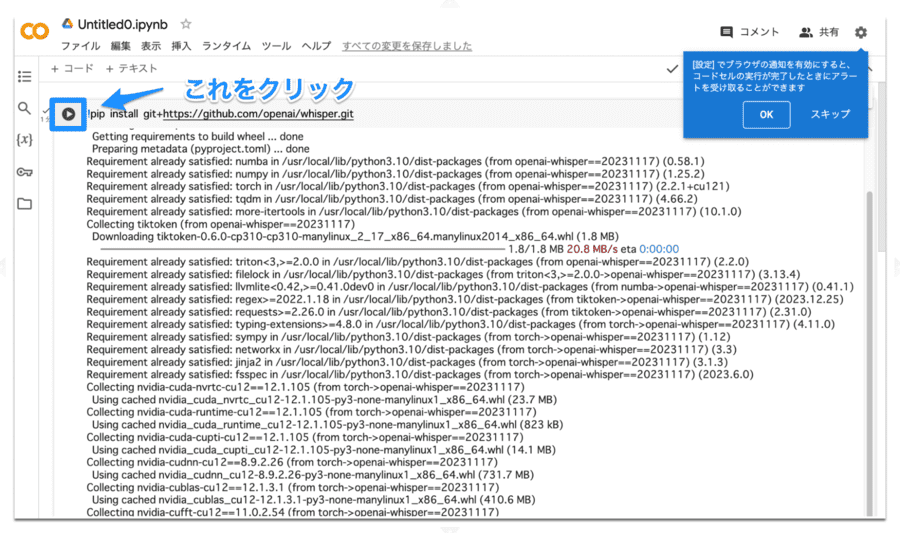
以下のようなコードの羅列が表示されていたら問題ありません。
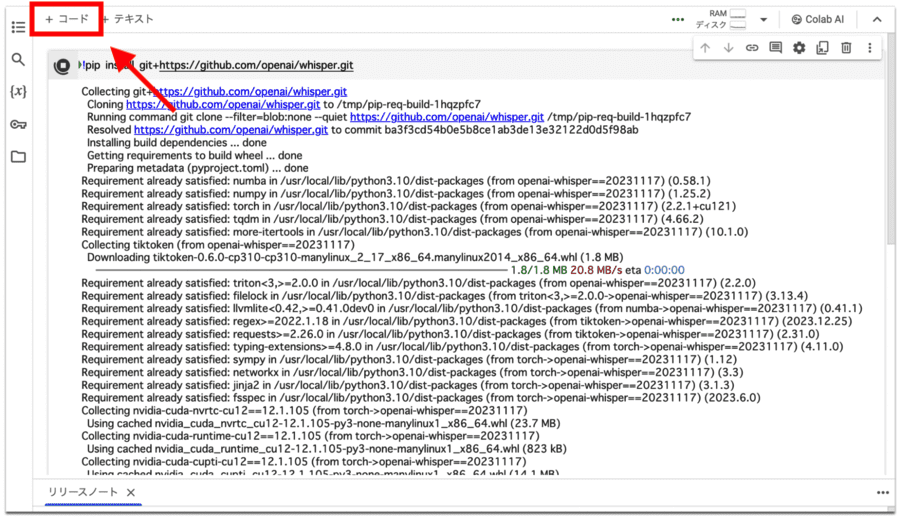
コードを追加する
続いてWhisperインポートの作業に入ります。画面左上の「+コード」をクリックしましょう。
Whisperを導入する
上記手順を実行すると、画面下部にスライドし、コーディング入力用のテキストボックスが表示されます。表示された場所に「import whisper」をコピーして入力しましょう。
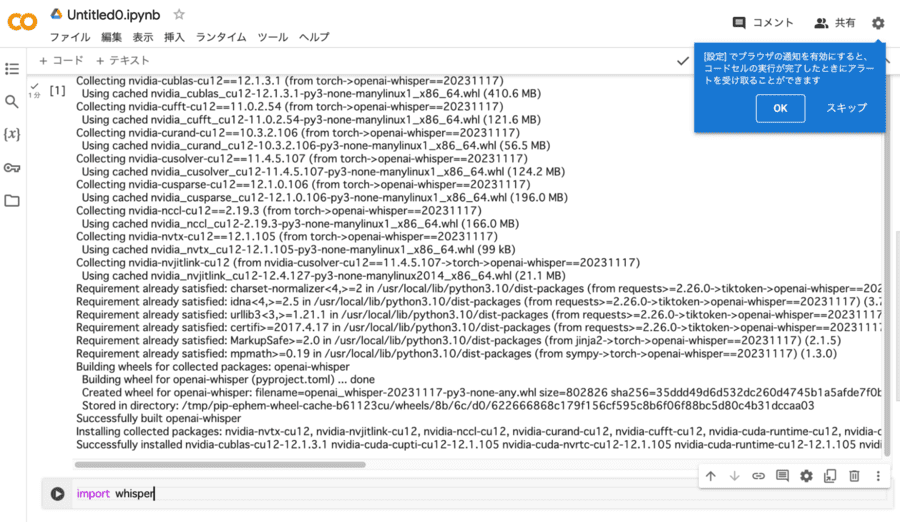
入力できたら、テキストボックス左側の再生ボタンをクリックします。これで、WhisperをGoogle Colaboratoryに導入できるはずです。
GitHub版を利用したい場合
WhisperにはGitHub版があります。しかしこちらを利用する場合、Pythonを利用するうえで欠かせないVENVというツールをきちんと使えるだけの技量が求められます。
したがってPythonの導入に不安がある場合は、上述したGoogle Colaboratoryを利用するのをおすすめします。
GitHubの導入に関しては、以下の動画が参考となるでしょう。
ライブラリや仮想環境など、やや専門的な単語が出てくるため、やや難解にはなります。
Whisperに関するよくある質問

本記事ではWhisperに関して解説しました。ここではよくある質問に回答します。
- Whisperは無料で利用できますか?
- Whisperの認識精度は他のツールと比べて優秀ですか?
- Whisperの代替になるツールはありますか?
- どのモデルがおすすめですか?
それぞれ詳しく解説するので参考にしてください。
- Whisperは無料で利用できますか?
-
WhisperのGoogle Colaboratory版は無料で利用できます。

Google Colaboratoryは導入も簡単です。本記事の導入手順を参考にインストールしてください。
- Whisperの認識精度は他のツールと比べて優秀ですか?
-
Whisperの認識精度の評価はモデルによって異なります。
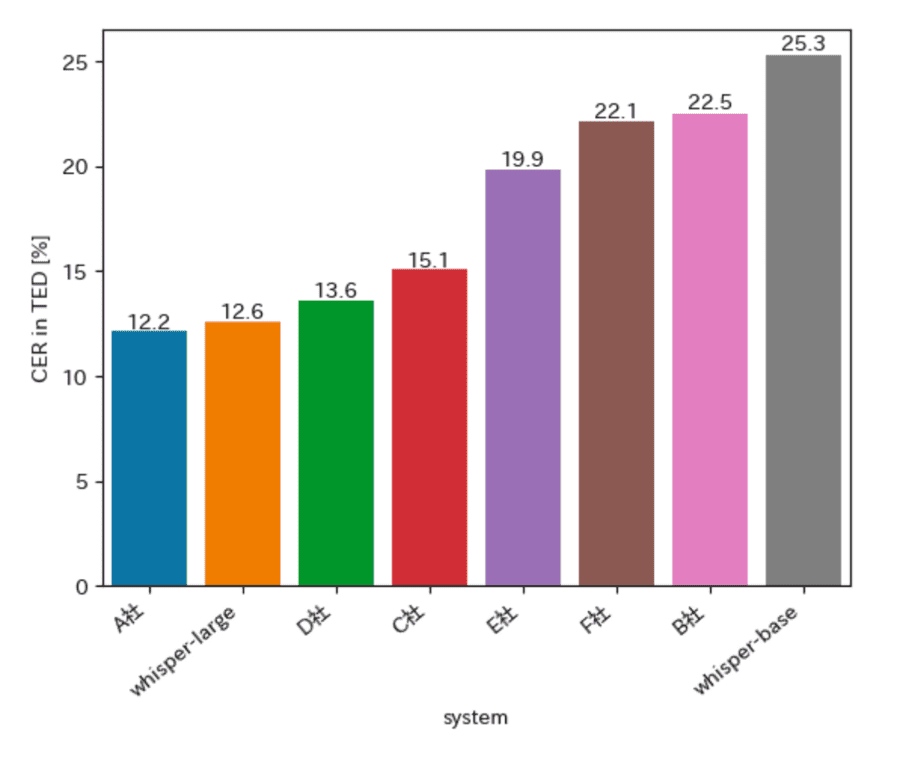
出典:RevComm Tech Blog これは、Whisperと他社の競合製品に同一の音声の書き起こしを指示し、CER(文字を間違えて出力してしまう確率)を比較したものです。
Whisperの最上級に当たるlargeモデルは、特に優秀なCERを記録しました。一方でbaseモデル(したから2番目の精度)は、他社の競合製品と比較してやや苦しい数値となっています。
baseがこの位置にあるなら、それの上位に当たるmediumとsmallは、largeまでのどこかに分布していると考えられます。
しがってlargeモデルの精度は他社と比較して高く、mediumとsmallは平均的。baseとtinyは、競合に対して劣る、と評価できるでしょう。
とはいえAPIである、多言語に対応しているといったメリットもあるため、そういう部分では、書き起こし専用ツールより優秀だとも考えられます。 - 代替になるツールはありますか?
-
Whisperの代替えとして、Notta(ノッタ)などのツールが有力です。
出典:notta nottaに音声ファイルをアップロードすれば、文字起こし、議事録自動作成などを実施できます。さらには内容の要約なども実施可能です。
さらに画面録画と文字起こしと要約を並行できる特別なビデオチャット機能も。利用料金は1,317円からと、Whisperと比較して驚くほど高いものではありません。
Whisperに何らかの問題を感じているなら、nottaの導入を検討してみましょう。
ただしnottaは「音声データを文字に起こすこと」に主眼を置いているものです。チャットボット構築、翻訳といった特殊な機能がない点には注意してください。
- どのモデルがおすすめですか?
-
使うべきモデルは、以下を参考にして判断するとよいでしょう。
モデル パラメータ Relative Speed(large=1) 使用感 tiny 39M ~32x Whisperにおける最小のモデル。処理速度は非常に高い。ただし漢字の誤変換や聞き間違い(同音意義語の取り違え)がやや多い。このあとにある程度の強度でリライトを実施するなら問題ない。 base 74M ~16x Tinyより処理速度は遅くなるが、正確性が向上する。誤変換の数は少なくなるものの、一般的な誤字脱字はある程度のこる small 244M ~8x 5つのモデルのうち中間に位置する。処理速度、精度とも平均的で非常に使いやすい。 Medium 769M ~2x 高い精度で音声認識できるようになる。漢字、カタカナ、ひらがな、いずれの場合でも問題なく認識可能。
しかし処理速度がやや長くなる。large 1550M ~1x Whisperにおける最大のモデル。処理速度は非常に低いものの、認識の精度はすべての音声認識モデルにおいてもトップクラス。単純に誤字脱字が少ないうえ、句読点なども適切に打つことが可能。 まず中間に位置するsmallを使ってみましょう。そして処理速度に課題があるならbase寄り、精度に問題があればMediumu寄りに軌道修正するのがおすすめです。

まとめ
本記事では音声認識モデルのWhisperに関して解説しました。最後に重要なポイントをおさらいしましょう。
- Whisperは、OpenAIがリリースした高性能は音声認識モデル
- 書き起こし、議事録の自動作成、インタビュー要約など、さまざまなアクションを実施可能
- さらにYouTube音声の文字起こしや機器の遠隔操作なども実施できる
- 日本語を高精度で認識でき、さらに利用料金も安い
- 99の言語に対応できるなどの点も魅力的
- Google Colaboratory版は利用が簡単かつ無料なので、まずはこちらの使用を推奨
これまで数多くの音声認識サービスがリリースされてきました。そのなかでも精度の高さと対応言語の広さ、APIとして使い勝手のよさを持つWhisperはかなり魅力的な存在です。
Google Colaboratory版なら、そこまで高度なPythonのスキルを持っていなくても十分利用できます。費用もかからないので、まずは試してみましょう。