





Stable Diffusionでイメージどおりの高品質な画像を生成するにはモデル選びが肝心です。
しかし、
- モデルの概要や種類から知りたい
- どのモデルを選べばいいのかわからない
- 自分でモデルを探す方法を知りたい
上記のような悩みを持っている方は多いでしょう。
モデルには多様な種類があり、生成したい画像の内容によって選ぶべきモデルデータが変わってきます。
今回は、モデルデータの種類や、アニメ系などのカテゴリに分けたモデルの一覧を紹介、解説します。
使用するモデルの選択に迷っている方は、ぜひ最後までご覧ください。
Stable Diffusionの概要やインストール方法については以下の記事を参照するとよいでしょう。

モデルデータの種類
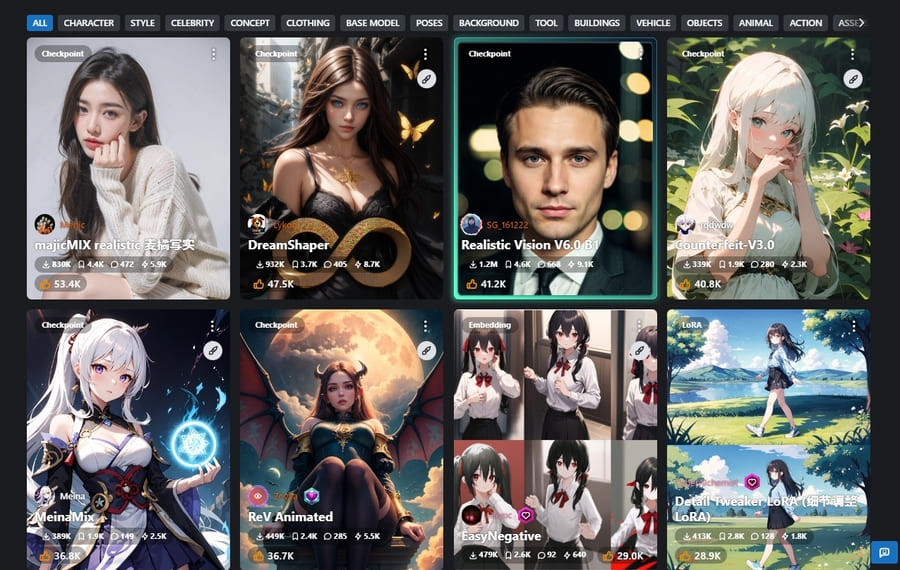
モデルとは、Stable Diffusionが画像を生成するとき参考にする学習データです。
モデルにはさまざまな種類があり、主に以下のようなデータが使用されています。
- Checkpoint|画像生成で必須となるモデル本体
- LoRA|特定の画風や要素に特化した追加学習データ
- VAE|画像生成を補助するツールの一種
- Embedding|学習データを追加できる埋め込みデータ
- Hypernetwork|LoRAやEmbeddingのように、追加学習するために使うモデルデータ
- Controlnet|人物のポーズを指定する際のモデルデータ
それぞれのデータの詳細を以下で解説していきます。
Checkpoint|画像生成で必須となるモデル本体

Checkpointは画像生成で必須となるモデルの本体です。
単純に「モデル」と言うときはCheckpointを指す場合が多いでしょう。
Checkpointによって生成できる絵の作風が大きく変わり、その種類は多種多様です。
アニメ系の絵で学習するとアニメの画像を生成しやすくなり、リアル系の絵で学習するとリアル系の画像生成に特化します。
学習した量が多いほど生成できるバリエーションが増えて精度が上がりますが、そのぶんCheckpointのファイルサイズは膨大に。
1GBを超えるCheckpointがほとんどなので、PCの空き容量には注意してください。
LoRA|特定の画風や要素に特化した追加学習データ

Low-Rank Adaptation(低ランク適応)の略称で、特定の画風や要素に特化した追加学習データです。
LoRAを導入して画像を生成することで、Checkpointの特徴を保ちながら新たな表現方法を追加できます。
例として、以下のような用途で使えるLoRAが用意されています。
- 特定のスタイルや画風を模倣する
- 特定のキャラクターを生成できるようにする
- 背景や表情、ポーズなどを追加する
LoRAのファイルサイズは1GBに満たないものが多いので、Checkpointと比べると新しいデータを導入しやすいでしょう。
複数のLoRAを組み合わせれば、オリジナリティのある画像を作りやすくなります。
VAE|画像生成を補助するツールの一種

Variational Auto-Encoder(変分オートエンコーダー)の略称で、画像生成を補助するツールの一種です。
VAEの有無によって、生成される画像の鮮明さや色味などが変わります。
使用するCheckpointとの相性が特に重要となるため、使うモデルごとに対応するVAEを使うようにしましょう。
一部のCheckpointには専用のVAEを使う前提のものが存在し、VAEを使用しないと低品質になってしまう場合も。
Embedding|学習データを追加できる埋め込みデータ

Embeddingは、学習データを追加できる埋め込みデータです。
LoRAとはデータの作り方などは異なりますが、プロンプトに書いて使用する点は共通しています。
ただし、ネガティブプロンプトに記述して使うデータは、Embeddingで作られるケースが多いようです。
通常のプロンプトに書いて使用する場合もあるため、逆効果にならないよう使い方に注意する必要があるでしょう。

Hypernetwork|LoRAやEmbeddingのように、追加学習するために使うモデルデータ

LoRAやEmbeddingのように、追加学習するために使うモデルデータです。
Checkpoint全体に影響を与えるため、追加した内容を安定して生成できるのが特徴。
LoRAやEmbeddingでの学習がうまくいかないときはHypernetworkも試してみるとよいでしょう。
ほかの追加学習データと比べてサイズが大きくなりやすいので要注意。
Controlnet|人物のポーズを指定する際のモデルデータ
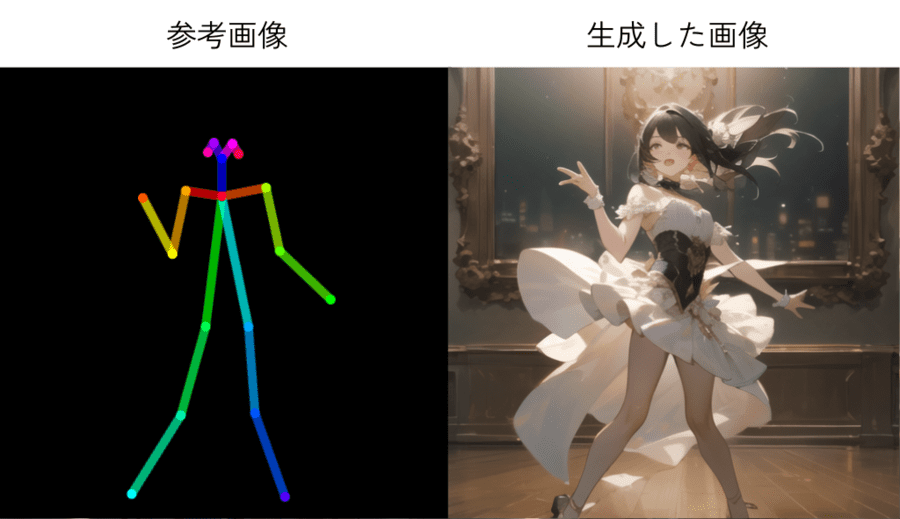
人物のポーズを指定したりするのに使えるControlNet用のモデルデータです。
ControlNetのモデルデータは種類によって動作が大きく異なり、以下のように用途が多岐にわたります。
- 画像等から検出した人物のポーズをもとに画像を生成する
- 元画像から抽出した深度情報や線画をもとに異なる画風で生成する
- 元画像を参照しつつ特定の要素を変更する
- 高解像度の画像を生成する(アップスケール)
ControlNetの機能を利用するには拡張機能を追加する必要もあるので、これらモデルの導入は上級者向けといえるでしょう。
狙ったポーズで生成しやすくなるため、画像生成に慣れたらControlNetのモデル導入を検討してみてください。
ちなみに、ポーズを指定できるControlNetモデルとしては、OpenPoseなどが有名です。

Stable Diffusionおすすめモデルのカテゴリ別一覧紹介

Stable Diffusionのモデルデータは、CivitaiやHugging Faceなどのサイトでダウンロードできます。
ダウンロードして入手できるおすすめのモデルを、以下のカテゴリに分けて紹介します。
- 実写・リアル系のCheckpoint
- アニメ系のCheckpoint
- 背景系のCheckpoint
- SDXLを利用したCheckpoint
- Checkpoint以外のモデルデータ
実写・リアル系のCheckpoint

実写系のリアルな画像を生成できるCheckpointのおすすめは以下のとおり。
| モデル名 | 特徴 |
|---|---|
| CyberRealistic | アジア系の画像を生成できる |
| yayoi_mix | 日本人の女性の画像を生成できる |
| Beautiful Realistic Asians | アジア人の画像を生成できる |
| RealBeautyMix | アジア系女性の画像を生成できる |
| XXMix_9realistic | 実写系の女性の画像を生成できる |
| Henmix_Real | アジア系女性の画像を生成できる |
アニメ系のCheckpoint

アニメ系のCheckpointは作風が変わりやすいので、以下のモデルを使って実際に画像生成を一通り試してみるのをおすすめします。
| モデル名 | 特徴 |
|---|---|
| Pika’s New Generation | 繊細な画像を生成できる |
| AbyssOrangeMix2 | アニメ風の画像を生成できる |
| 99mix | アニメ塗りの画像を生成できる |
| Nostalgia-clear | ノスタルジックな雰囲気の画像を生成できる |
| Pastel-Mix | パステル調の画像を生成できる |
| Goofball Mix | リアル寄りの画像を生成できる |
背景系のCheckpoint

背景だけの画像を生成したいときは、以下のようなモデルを使うとよいでしょう。
| モデル名 | 特徴 |
|---|---|
| architecture_Urban_SDlife_Chiasedamme_V6.0 | リアルな背景を生成できる |
| ForgeSaga Landscape | アニメ風の背景を生成できる |
| Home Rooms Decoration | リアルな室内の背景を生成できる |
| kaodiiLandscapeMix – day | 昼の背景を生成できる |
| kaodiiLandscapeMix – night | 夜の背景を生成できる |
| Urban Streetview | リアルな街の背景を生成できる |
SDXLを利用したCheckpoint

Stable Diffusionの最新モデルであるSDXL(Stable Diffusion XL)を利用して学習されたCheckpointでは、以下のモデルがおすすめです。
| モデル名 | 特徴 |
|---|---|
| Juggernaut XL | リアル系の画像を生成できる |
| DreamShaper XL | リアル系の画像を生成できる |
| 万象熔炉 | Anything XL | アニメ系の画像を生成できる |
| Animagine XL 4.0 | アニメ系の画像を生成できる |
| Landscape Realistic Max (SDXL) | リアルな背景を生成できる |
| Animat background v1 | アニメ系の背景を生成できる |

SDモデルとSDXLモデルの違い
Stable DiffusionとSDXLのモデルには以下のような違いがあります。
- 描画に関わるパラメータ数
- 学習に用いる画像のサイズ
- 高品質な画像を生成するのに必要なプロンプトの量
- 必要なPCスペック
- 対応しているLoRA
SDXLはパラメータ数や画像サイズが大きくなり、簡単で短いプロンプトでも高品質な画像を生成しやすくなっています。
ただしGPUのメモリが12GB以上必要であったり、Stable Diffusionで使えるLoRAに対応できなかったりするデメリットも。
新しいWebUIであれば両方のモデルが使えるので、実際に画像を生成し、使用するPCにモデルが合っているか確認してみてください。
Checkpoint以外のモデルデータ

おすすめのLoRA、VAE、Embedding、Hypernetworkをまとめて紹介します。
| モデル名 | 特徴 |
|---|---|
| Artista Watercolor | 水彩のエフェクトを追加するLoRA |
| Anime Realism Control LoRA | アニメ系とリアル系を調整するLoRA |
| vae-ft-mse-840000-ema-pruned.safetensors | 公式(Stability AI)から配布されているVAE |
| kl-f8-anime2 VAE | kl-f8-anime2モデル向けに作られたアニメ系のVAE |
| EasyNegative | 低クオリティなアニメ画像の生成を防ぐEmbedding |
| Deep Negative V1.x | リアル系で奇怪な体が生成されないよう抑えるEmbedding |
| [LuisaP] Sci-fi/Hard surface | リアルな質感の画像を生成できるHypernetwork |
| [LamaPanama] Waven Chibi Style | デフォルメされた人物を生成できるHypernetwork |
モデルデータの探し方とダウンロード方法
おすすめしたモデルデータが自分に合わなかったり、新しいモデルデータをダウンロードしたかったりするときは、以下の手順で探してみてください。
- モデルをダウンロードできるサイトにアクセスする
- 一覧表示するモデルにフィルターをかける
- モデルの詳細を確認する
- データをダウンロードして指定の場所に置く
モデルをダウンロードできるサイトにアクセスする
モデルデータをダウンロードしたり配布したりできるサイトにアクセスします。
よく使われているサイトは以下の2つです。
どちらのサイトを利用しても構いませんが、サンプル画像が一覧表示されるCivitaiのほうがおすすめです。
公式のCheckpointなど、Civitaiで配布されていないモデルをHugging Faceでダウンロードするとよいでしょう。

一覧表示するモデルにフィルターをかける
モデルの数は数千以上も用意されているので、フィルターや並び替えの機能を使って表示するデータを絞ります。
モデル一覧の右上にある「Filters」をクリックするとフィルターを選択できるので、表示させたいものを選んでください。
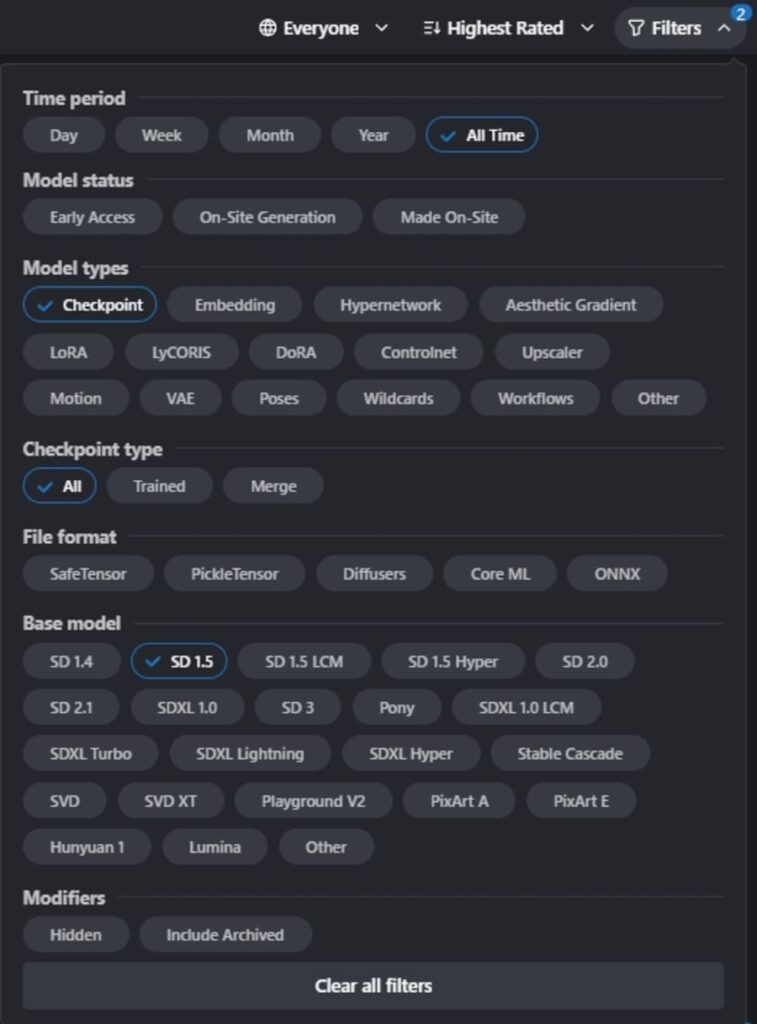
以下の項目を選択すれば、目的のモデルを見つけやすくなるでしょう。
- Time period(期間)
- Model types(モデルデータの種類)
- File format(データファイルの形式)
- Base model(学習のベースとなるモデル)
Stable DiffusionのCheckpointを探すときは、Model typesは「Checkpoint」を、Base modelは「SD 1.5」を選ぶ……といった形で指定します。
「Filters」の横にあるソート項目を変更して並び順を変えれば、さらに探しやすくなるでしょう。
| ソート項目 | 意味 |
|---|---|
| Highest Rated | 評価レートが高い順 |
| Most Downloaded | ダウンロード数が多い順 |
| Most Liked | いいねの数が多い順 |
| Most Discussed | コメント数が多い順 |
| Most Collected | コレクション(お気に入り)された数が多い順 |
| Most Images | Civitai上で生成された画像の数が多い順 |
| Newest | 新しくアップロードされた順 |
| Oldest | 早くアップロードされた順 |
気になるモデルを見つけたら、詳細画面で細かい情報を確認します。
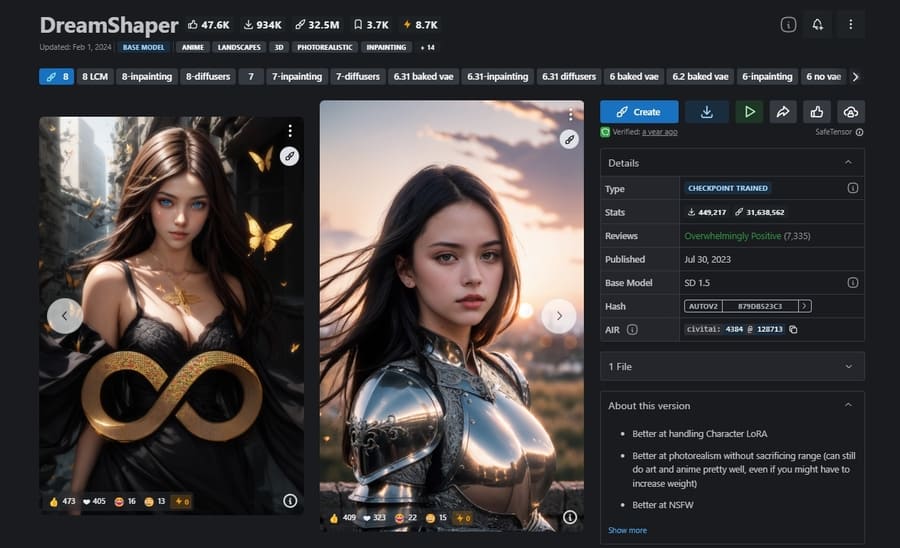
とくにCheckpointはデータサイズが大きいので、ダウンロードの手間がかからないよう事前にしっかりとチェックするのがおすすめです。
具体的には、以下のような情報を確認するとよいでしょう。
- 学習に使用したモデル
- モデルを使ってできること
- 使い方および注意事項
- モデルの使用条件(商用利用の可否など)
- 組み合わせる必要がある別データ
- データを使うためのトリガーワード
Hugging Faceを利用するときは「Model card」タブの内容を読んでください。
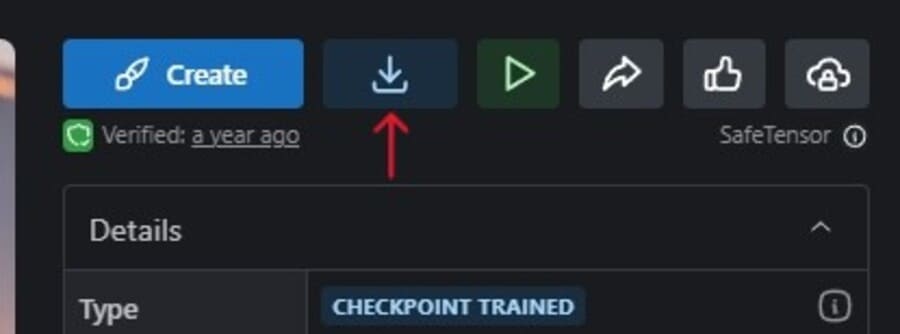
詳細を読み問題がないと判断できたら、右上のダウンロードボタンからダウンロードします。
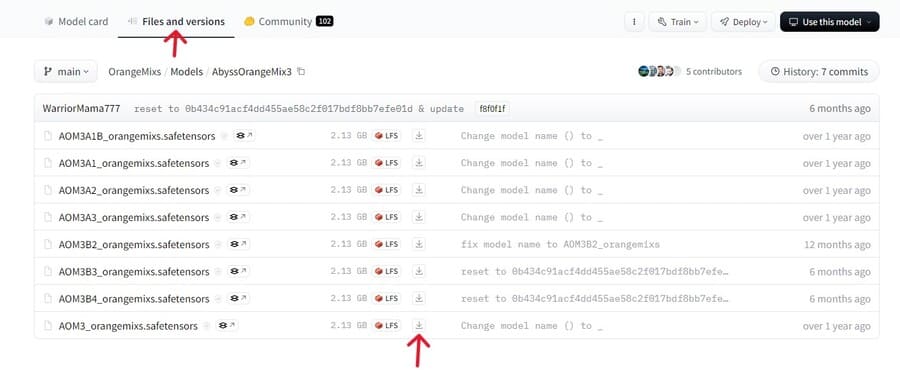
Hugging Faceでモデルをダウンロードするときは「Files(and versions)」タブに切り替えてsafetensorsファイルのダウンロードボタンを押してください。
ダウンロードできたファイルは、モデルの種類に応じた場所に移動させましょう。
| モデルの種類 | 場所 |
|---|---|
| Checkpoint | (Stable Diffusionの場所)\models\Stable-diffusion |
| LoRA | (Stable Diffusionの場所)\models\Lora |
| VAE | (Stable Diffusionの場所)\models\VAE |
| Embedding | (Stable Diffusionの場所)\embeddings |
| Hypernetwork | (Stable Diffusionの場所)\models\hypernetworks |
| Controlnet | (Stable Diffusionの場所)\models\ControlNet |
Embeddingを置くフォルダのみmodelsフォルダの外にあるので要注意です。
Stable Diffusionのモデルに関するQ&A
Stable Diffusionのモデルに関する、よくある質問と回答を紹介します。
- モデルの使い方は?入れ方や切り替え方がわかりません
- モデルを商用利用できますか?ライセンスを確認するには?
- 著作権の問題はありますか?
- モデルをマージ・学習させる方法は?
- モデルの使い方は?入れ方や切り替え方がわかりません
-
CheckpointはWebUIの左上で切り替えられます。

EmbeddingやHypernetwork、LoRAは、新しいWebUIでネガティブプロンプトに表示されるタブのTextual Inversion、Hypernetworks、LoRAにそれぞれ表示されます。
表示されているモデルを使いたいときにデータをクリックして、プロンプトまたはネガティブプロンプトにトリガーとなるワードを追加しましょう。
Controlnetのモデルは、画像生成のシード値の下にある「ControlNet」タブ内で変更することが可能です。
- モデルを商用利用できますか?ライセンスを確認するには?
-
モデルを使用できる範囲はデータによって異なるため、一つひとつ確認する必要があります。
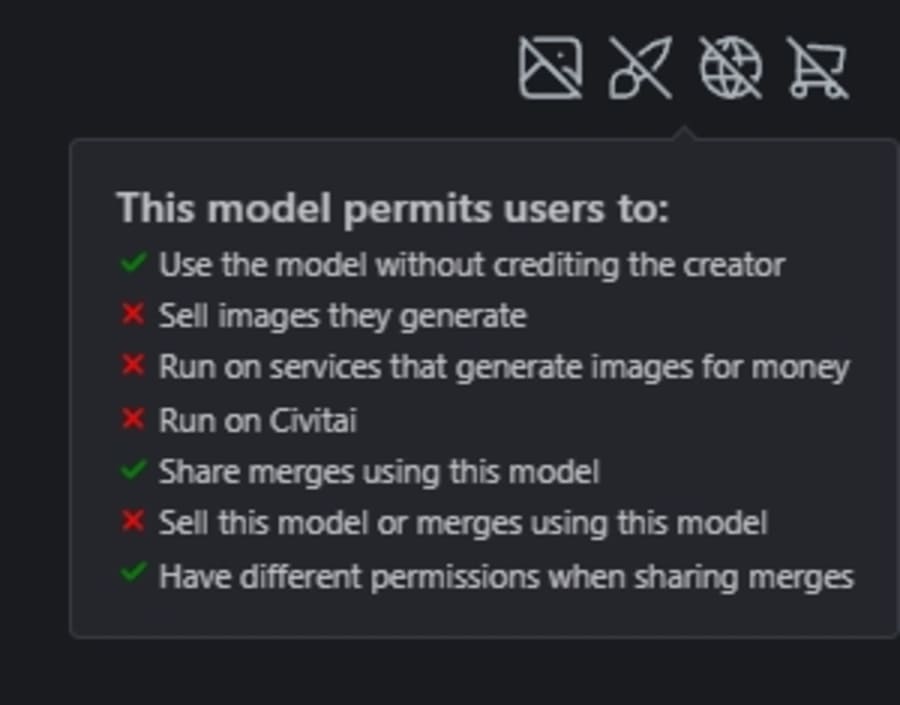
Civitaiの場合、詳細画面の右下にライセンスや制約などが表示されています。
出典:Civitai 以下のように用途別の可否が書かれているので、予定している使い方ができるか必ずチェックしてください。
項目 意味 Use the model without crediting the creator このモデルの作者の名前を表記する必要があるか Sell images they generate 生成した画像の販売(商用利用)が可能か Run on services that generate images for money このモデルを用いた生成サービスで収益化できるか Run on Civitai ダウンロードする前にCivitai上で実行できるか Share merges using this model このモデルをマージして再配布できるか Sell this model or merges using this model このモデルまたはマージしたものを販売できるか Have different permissions when sharing merges このモデルをマージしたとき違う制約に変更できるか なお、今回紹介したすべてのおすすめモデルは、生成した絵の商用利用が認められています。
- 著作権の問題はありますか?
-
商用利用できるモデルを使ったとしても、著作権を侵害する可能性はあります。
たとえば、特定のキャラクターを学習しているLoRAは、版権キャラクターの画像を生成する目的で作られている場合が多い傾向です。
また、アニメ系のCheckpointは最近のアニメ画像を使って学習しているパターンもあるため、著作権を侵害するつもりがなくても似た画像を生成してしまうかもしれません。
非営利的な個人利用であれば大きな問題になりませんが、商用利用するのであれば注意してください。
- モデルをマージ・学習させる方法は?
-
Stable Diffusion WebUIを利用して、モデルをマージさせたり学習させたりできます。
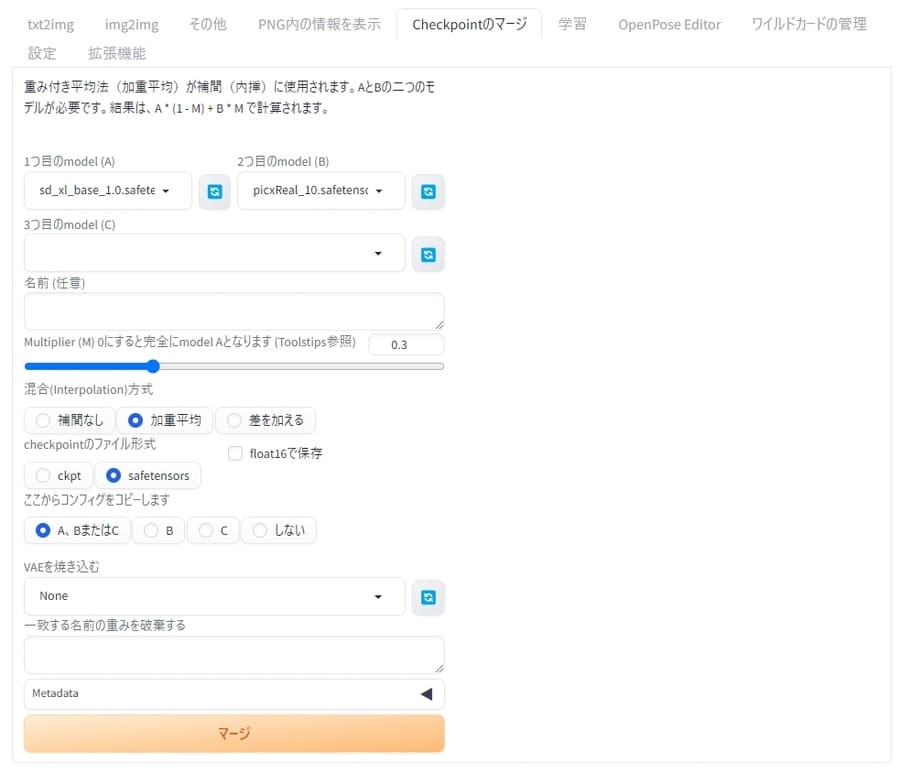
WebUIで「Checkpointのマージ」タブを選択し、2つまたは3つのモデルを選んで「マージ」ボタンを押せば、複数の学習内容が組み合わさった新しいCheckpointが作れます。
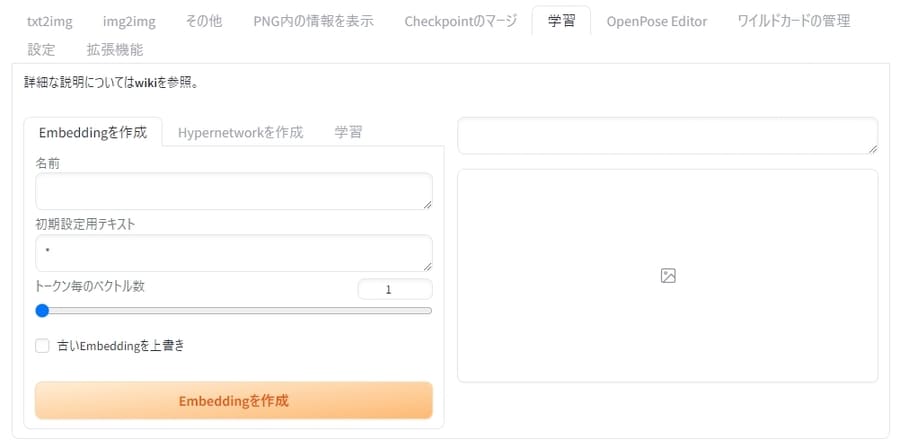
「学習」タブでは、EmbeddingやHypernetworkを作成したり、アップロードした画像で学習させたりすることが可能。
気に入ったモデルが見つからないときは、これらの機能を使って自分だけのモデル作成に挑戦してみるとよいかもしれません。
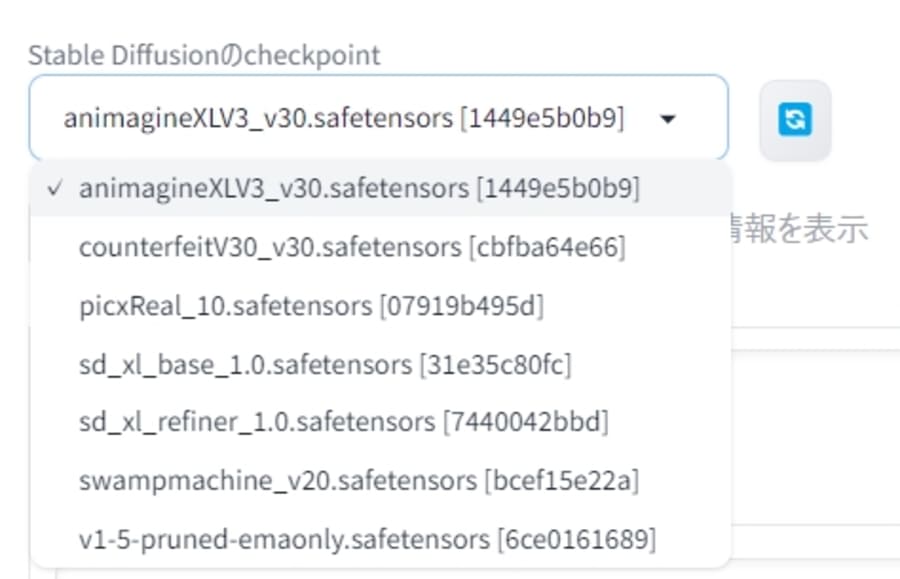
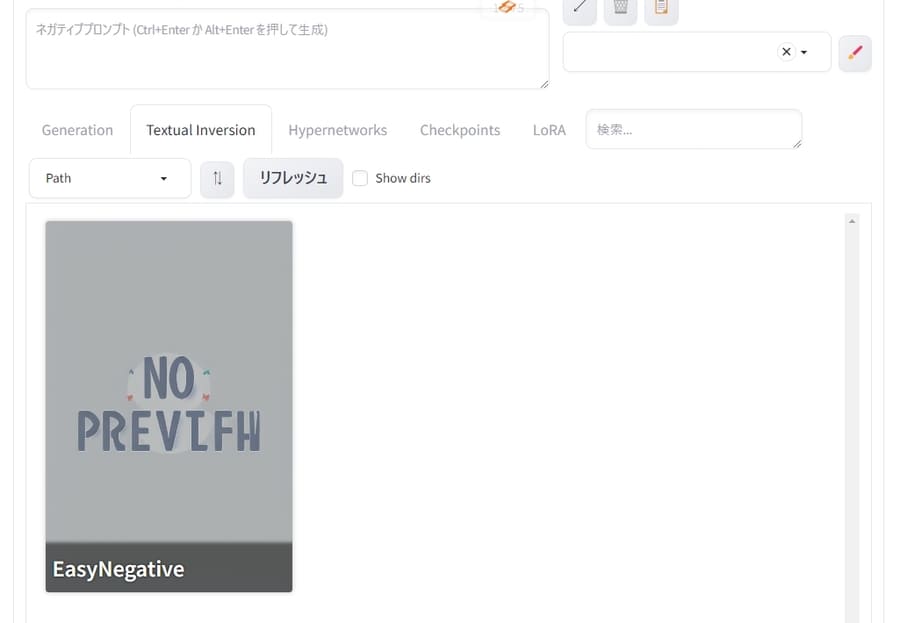
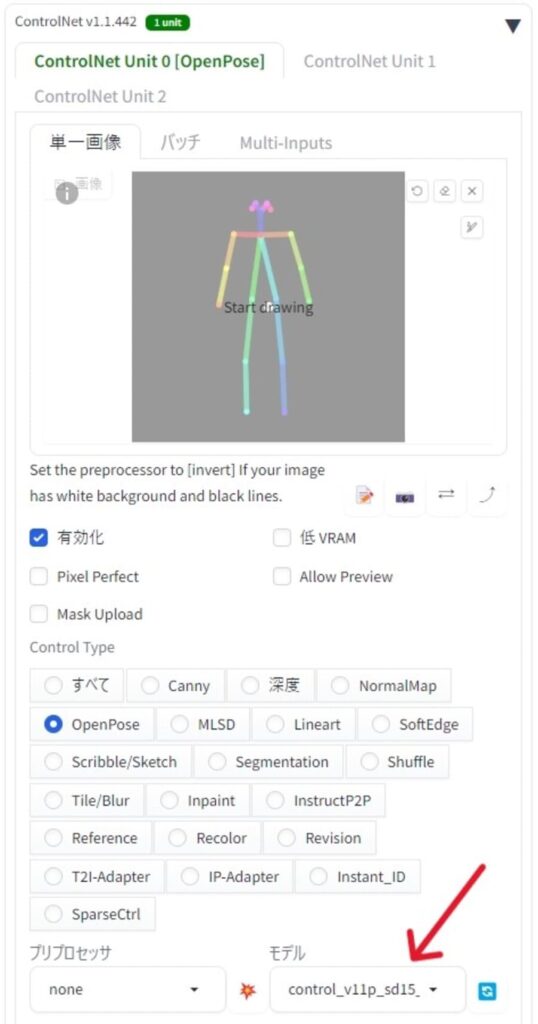
まとめ

本記事では、Stable Diffusionのモデルについて解説しました。
最後に、記事の内容をおさらいしておきましょう。
- CheckpointやLoRAなど、モデルには多様な種類がある
- 目的に合わせて複数のモデルデータを組み合わせて使うことが重要である
- CivitaiやHugging Faceで新しいモデルを入手できる
- 商用利用の可否や著作権の問題には注意が必要である
ネット上には数千を超えるモデルデータが公開されており、追加学習データを併用すれば自分だけの組み合わせ方も見つけられるでしょう。
さまざまな画像を生成しながらモデルデータの特徴を掴み、さらなるクオリティアップを目指しましょう。







