





AI画像生成ツールを語る上で外せないのが、2022年8月にStability AIから公開されたStable Diffusion(ステイブルディフュージョン)です。
しかし、以下のように思っている人もいるでしょう。
- Stable Diffusionの詳細や特徴が知りたい
- 無料で使う方法が気になる
- ローカル環境(自分のPC)での準備方法や使い方がわからない
結論から言うと、Stable Diffusionは自由度の高い画像生成AIツールで、オンラインサービスやローカル環境から無料で利用できます。
今回の記事では、Stable Diffusionの概要やローカル環境の構築方法、使い方を解説します。
無料で使えるオンラインサービスについても触れているので、ぜひ本記事を読んでみてください。

Stable Diffusionとは?概要と特徴

ここでは、Stable Diffusionの特徴を5つ解説します。
- オープンソースの画像生成AIツール
- プロンプト(呪文)を入力するだけで簡単に使える
- 利用方法は大きく分けて3通り
- モデルデータを変更して作風を変えられる
- 拡張機能や設定によってカスタマイズできる
1.オープンソースの画像生成AIツール
Stable Diffusionとは、オープンソースで公開されている画像生成AIツールです。
オープンソースのツールは誰でも自由に使えるので、様々なオンラインサービスで利用されています。
たとえば、以下のサービスでStable Diffusionが使用できます。
- Stable Diffusion Online|会員登録不要、無料(有料プランあり)
- Dream Studio|Stability AI社が運営、25クレジット無料(チャージ制)
- mage.space|設定項目が非常に豊富、無料(有料プランあり)
自分のPCに導入して画像を生成したり、独自にカスタマイズしてネット上に公開したりすることも可能です。
2.プロンプト(呪文)を入力するだけで簡単に使える
Stable Diffusionの基本的な使い方は、プロンプト(呪文)と呼ばれるAIへの命令文を入力するだけ。
たとえば、「2 girl」と入力すれば2人の少女が描かれた絵を生成できます。
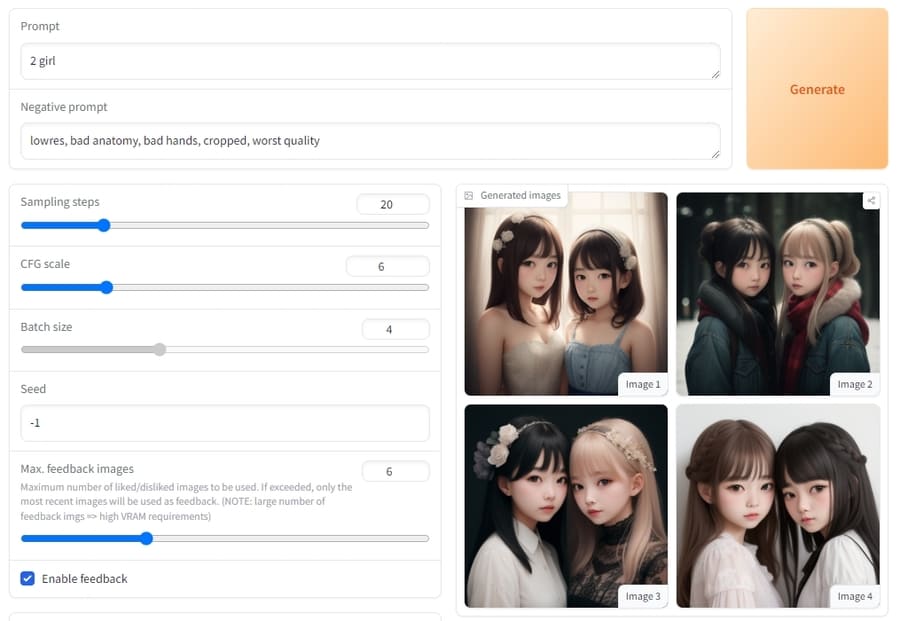
背景や状況などの詳細を含めてプロンプトに入力すれば、思い通りの絵を生成しやすくなります。
日本語で入力しても絵は生成されますが、英語で入力したほうがプロンプトの内容が反映されるようです。
プロンプトの詳細をまとめている別記事があるので、こちらも参考にしてください。

3.利用方法は大きく分けて3通り
Stable Diffusionを利用する方法は大きく分けて3通りあり、それぞれ特徴が異なります。
| 利用方法 | メリット | デメリット |
|---|---|---|
| オンラインサービス(Stable Diffusion Onlineなど)を利用 | ・環境構築が不要 ・クオリティの高い絵を生成しやすい ・サービスによっては無料で使える | ・使える機能が限られている ・利用できるモデルデータが決まっている ・サーバーが混雑すると生成速度が遅くなる |
| クラウドストレージ(Google Colaboratoryなど)に導入 | ・スペックが低いPCやスマホでも利用できる ・前準備としてすることが少ない ・生成速度が速い | ・基本的に有料プランへの加入が必要 ・立ち上げるのに時間がかかる |
| ローカル環境(自分のPC)で構築 | ・無料で使える(要電気代) ・生成物の内容や数に制限がない ・自由にカスタマイズできる | ・環境の構築に手間がかかる ・生成速度はPCスペックに依存する |
オンラインサービスやクラウドストレージを利用すると、比較的簡単にStable Diffusionを使い始められます。
しかし、使える機能が限られていたり、NSFW画像を出力できなかったりと制限が多くなるデメリットも。
性的表現や暴力表現などを含み、閲覧に注意が必要な画像。
ローカル環境を構築できる場合は、本記事の「Stable Diffusionをローカル環境で設定・構築する手順」項目を読んで挑戦してみてください。
スマホから無料かつ簡単に使うならオンラインサービスがおすすめ
とりあえず試してみたいというのであれば、スマートフォンからでも無料で使えるオンラインサービスがおすすめです。
無料で使えるオンラインサービスにはStable Diffusion Onlineなどがあります。

Stable Diffusion Onlineの使い方を解説している別記事があるので、こちらを参考に利用してみてください。

使える機能が物足りない場合は、別のオンラインサービスやローカル環境の利用しましょう。
Google Colaboratoryの無料版では利用できない
Google Colaboratory(通称Google Colab)で利用する場合、無料版ではStable Diffusionを使用できません。
以前は、Stable Diffusionをクラウドストレージで利用する際の定番として、無料で使えるGoogle Colaboratoryが利用されていました。
しかし、Stable Diffusionの利用量が多くなりすぎたとして、2023年4月頃から無料版での利用が規制されています。
以下は2023年4月21日にXに投稿された、Google ColaboratoryプロダクトリーダーChris Perry氏のポストです。
日本語訳:
私たちは、無料ユーザー向けのインタラクティブなノートブック計算を優先しています。しかし、Stable Diffusion WebUIの利用が非常に増加し、私たちのチームの予算ではこの利用増加をサポートすることができません。
クラウドストレージに導入する際は、Google Colaboratoryの有料プランや、別のサービス(Paperspaceなど)を利用しましょう。
ただ、現在利用できるクラウドストレージも、いずれ規制される可能性がある点には注意が必要です。
4.モデルデータを変更して作風を変えられる
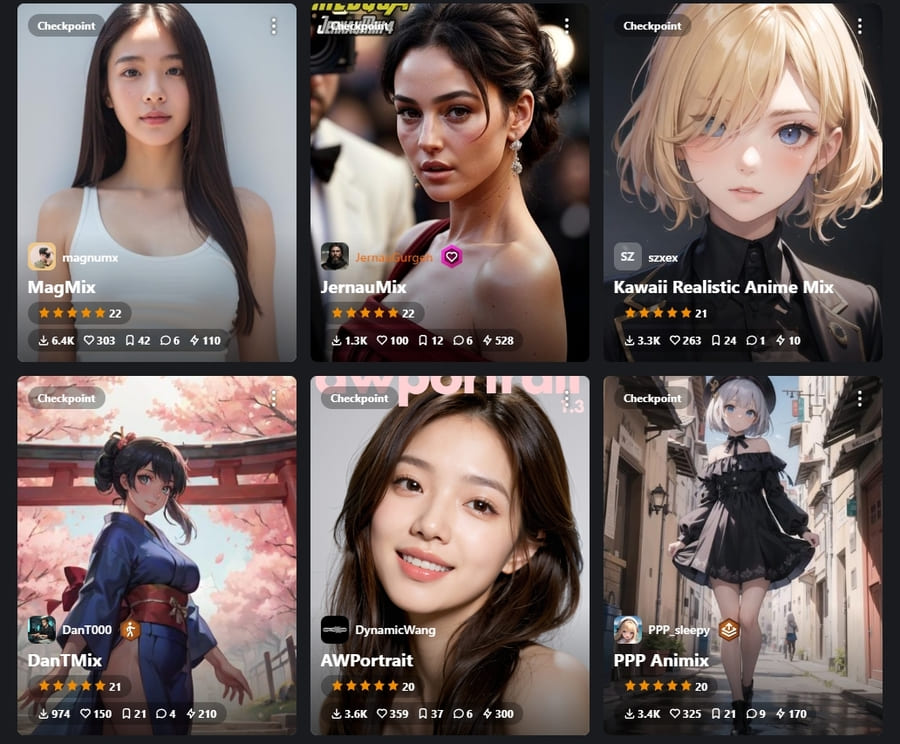
絵のベースとなるモデルデータを変更すれば、好きな作風の画像を生成できます。
モデルデータによって学習に使った画像の特徴や量が異なるため、同じプロンプトでも生成される絵が変わります。
たとえば、実写のような絵を生成したいときは実写系が得意なモデルデータを、背景の絵が欲しいときは背景をメインに学習したモデルデータを使うとよいでしょう。
モデルデータのサイズは1GBを超えるものがほとんどなので、PCの空き容量には注意してください。
気に入ったモデルデータが見つからないときは自作することも可能です。
モデルデータの作り方には以下の2通りがあり、どちらの方法もローカル環境のStable Diffusion内で実行できます。
- 既存のモデルデータをマージ(合成)する
- 用意した画像を使って学習させる
専門的な知識が必要な部分もあるので、モデルデータの作成方法については割愛します。
おすすめのモデルについて紹介している記事があるので、参考にしてください。

5.拡張機能や設定によってカスタマイズできる
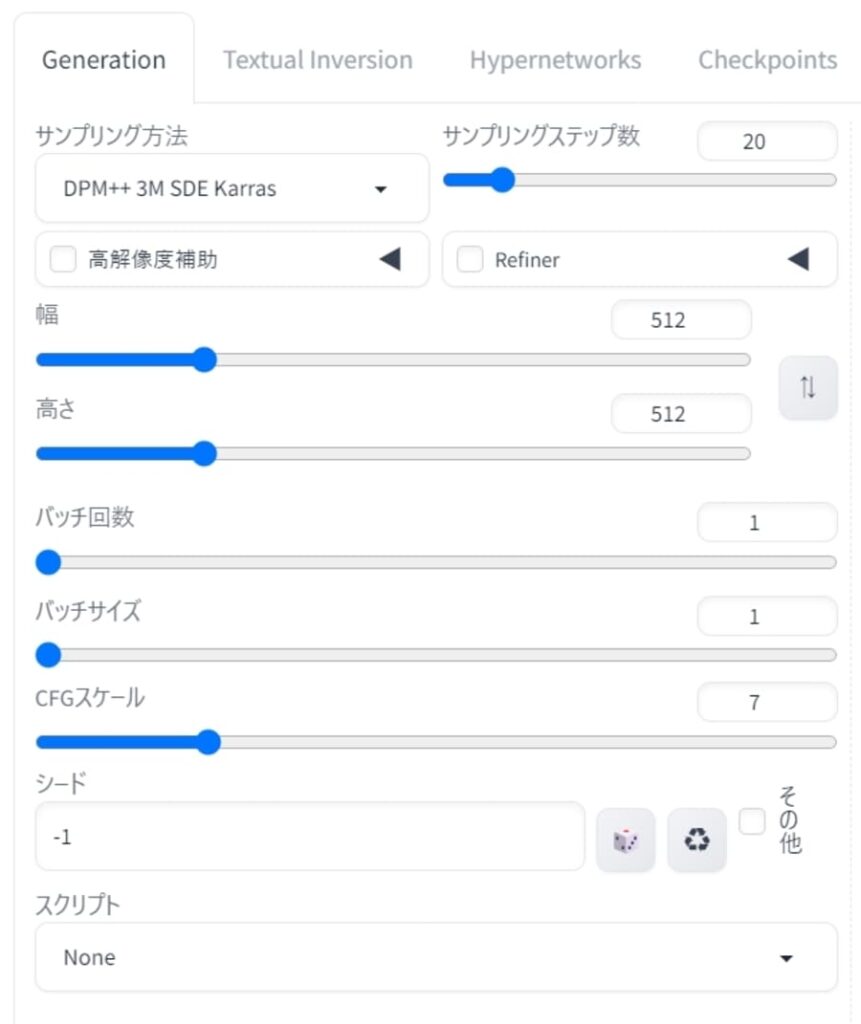
なかなか思い通りの絵を生成できないときは、設定を変更してみましょう。設定を理解してうまく調整できるようになると、生成できる絵のバリエーションに幅が出ます。
設定できる項目が多くて大変かもしれませんが、1〜2個を変えてみるところから始めてみてください。
追加で導入できる拡張機能を含めれば、イメージした絵がさらに作りやすくなるはずです。
おすすめの拡張機能の一例
Stable Diffusionを使う際は、以下の拡張機能を導入するとよいでしょう。
| 拡張機能の名前 | できること |
|---|---|
| localization-ja_JP | ツール全体の表示を日本語化できる |
| ControlNet | 人物のポーズを指定できる |
| Prompt Translator | プロンプトを自動的に翻訳する |
とくに、日本語化する拡張機能を有効化すれば、ツールがぐっと使いやすくなります。
使い方を解説する前にインストール方法を説明するので、ツールを起動できたら最初に導入してみてください。
人物のポーズを指定できる拡張機能ControlNetについては以下の記事で解説しているので、参考にすると良いでしょう。


Stable Diffusionをローカル環境で設定・構築する手順

ここでは、導入が難しいもののメリットが大きい、ローカル環境の構築方法を解説します。
以下の手順でStable Diffusion webUIを使えるようにしましょう。
- Python 3.10をインストールする
- Gitをインストールする
- Stable Diffusion webUIをダウンロードする
- webui-user.batを起動させる
- 必要なモデルデータを手に入れる
環境の構築自体は手順4で完了しますが、標準以外のモデルデータが欲しいのであれば手順5までおこなってください。
ーカル環境でStable Diffusionを利用する際は、以下のスペックをもつPCを用意しましょう。
| OS | Windows ※一部のMacも可 |
| GPU(グラフィックボード) | VRAMが12GB以上 |
| メモリ | 16GB以上 |
| ハードディスク(HDDおよびSDD) | 10GB以上 |
M1チップやGPUを搭載していれば、MacのPCでもStable Diffusionを構築できます。
とはいえ、高性能なGPUやメモリを買い替えたり増設したりしやすいWindow PCがおすすめ。
GPUを買い替える場合は、必要なスペック・電源が足りているか確認してください。
使っているPCによっては、xformerを活用してスペック不足を補える可能性も。

Python 3.10をインストールする
まずは、Stable Diffusionのプログラムを動かすのに必要なPythonをインストールします。
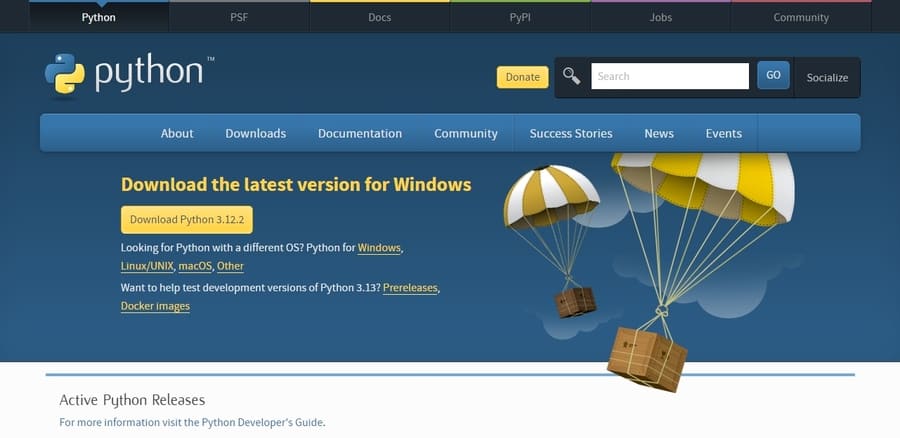
公式サイトのダウンロードページでバージョン3.10を選択して、インストーラーをダウンロードしてください。
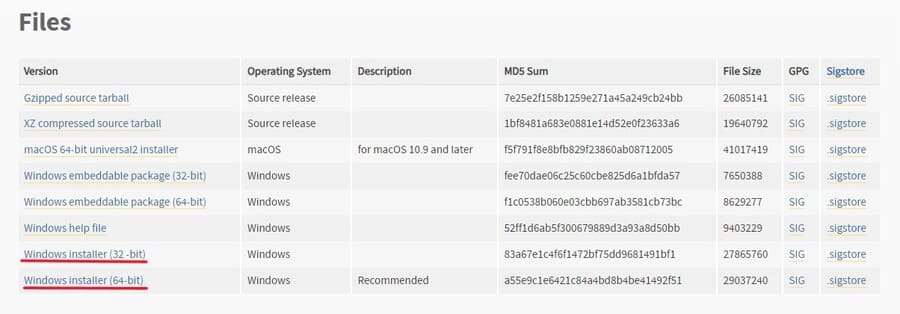
最新バージョンでは動かない可能性があるので注意してください。ダウンロードできたらインストーラーを実行し、インストールを完了させましょう。
「Install Now」を押す前には、「Add python.exe to PATH」のチェックを付けてください。
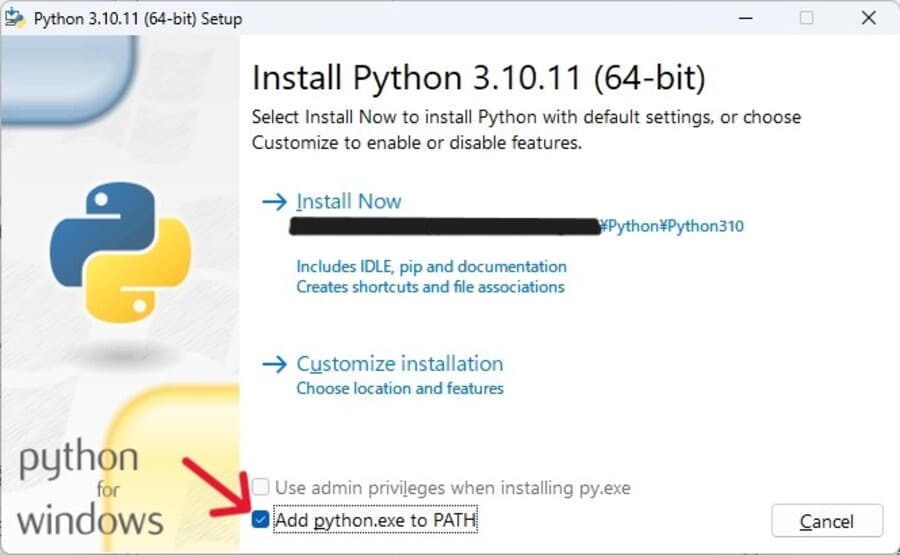
チェックを入れ忘れた場合は、インストーラーをもう一度動かしてPythonを削除したうえで再度インストールするのが手っ取り早いでしょう。
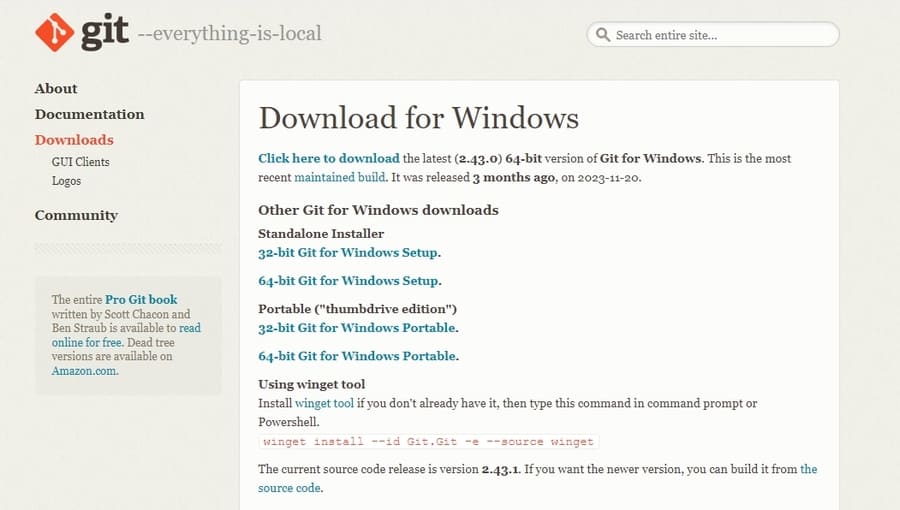
Gitをインストールする
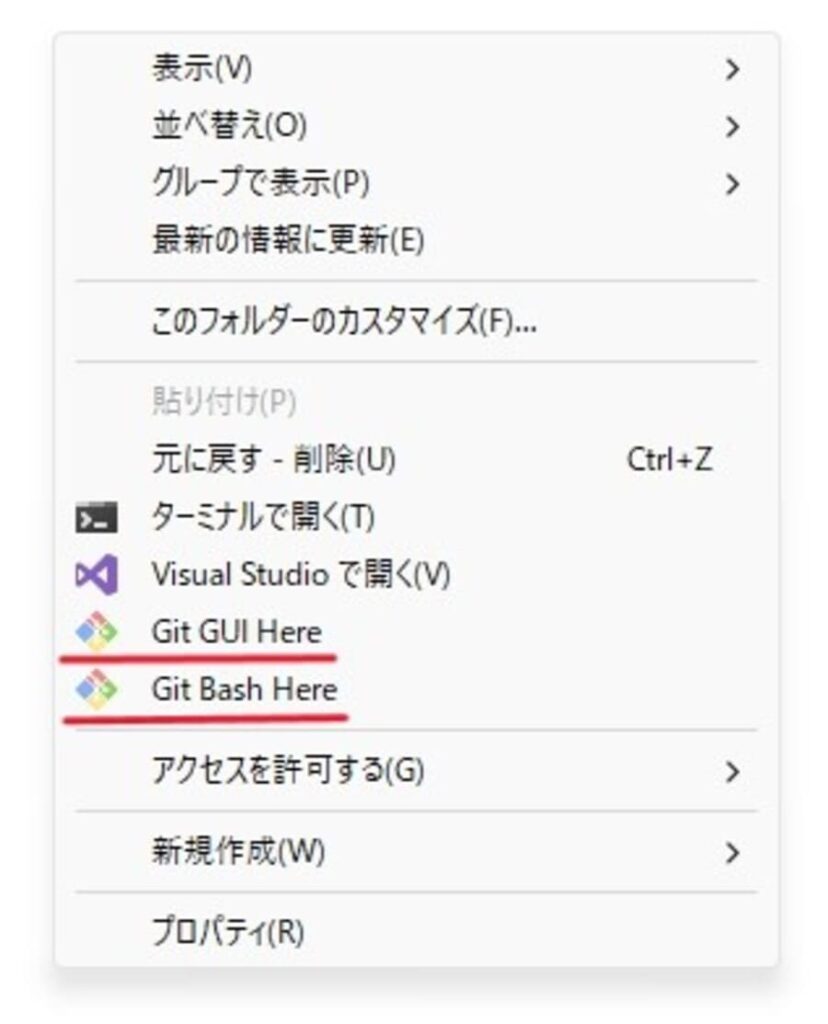
Stable Diffusion webUIをダウンロードする
ここまで準備が整ったら、いよいよStable Diffusionを使うためのツールをダウンロードします。
インストールするツールは、ローカル環境で構築する際の定番となっている、AUTOMATIC1111のStable Diffusion webUIです。

webUIをインストールしたい場所で、右クリックメニューから「Git GUI Here」を選択してください。するとGit GUIのウィンドウが表示されるので、Clone Existing Repositoryを選択します。
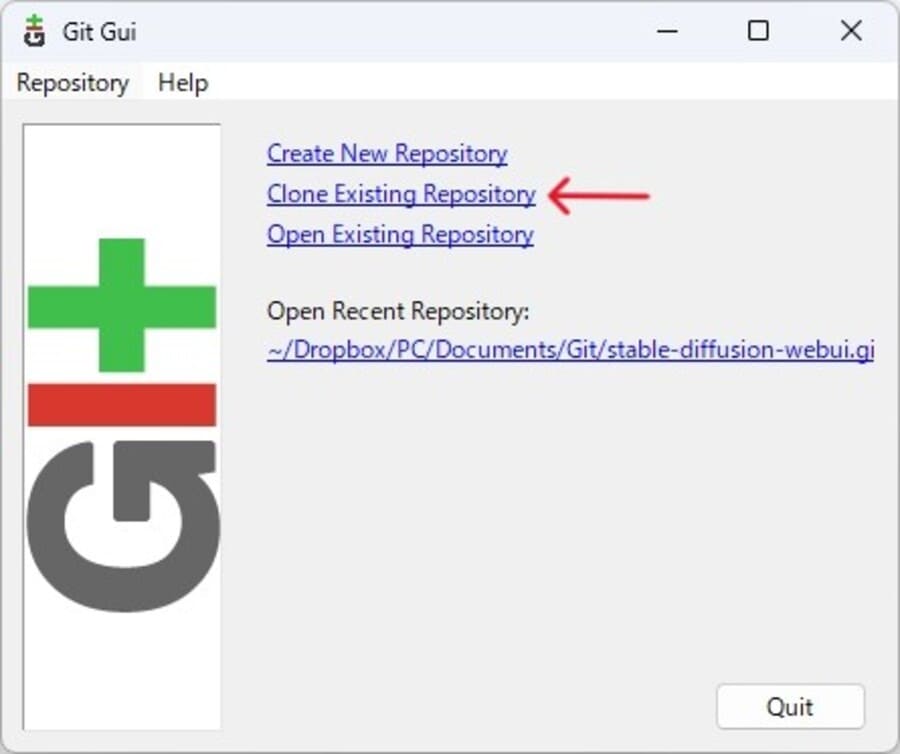
以下の項目を入力して、「Clone」ボタンを実行しましょう。
- Source Location:https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
- Target Direction:webUIを保存するフォルダの場所(※存在するフォルダを指定するとエラー)
ダウンロードが完了すると、指定したフォルダに必要なファイルが追加されています。
webui-user.batを起動させる
webUIのフォルダの中にあるwebui-user.batファイルを実行すれば、Stable Diffusion webUIが起動します。
ファイルを実行したときにプログラムの処理が始まるので、動作が止まるまで待ちましょう。
正常に処理が終わると、インターネットブラウザ(Google Chromeなど)で自動的にwebUIのページが開かれます。
もしローカルURLが表示されているのに自動的に開かない場合は、任意のインターネットブラウザ(Google Chromeなど)にURLを貼り付けてアクセスしてください。

無事にwebUIの操作画面が表示されれば、Stable Diffusionを使い始められます。
初回起動時は時間がかかる
webui-user.batを初めて開く際は、プログラムの処理が完了するのに時間がかかるので気を付けてください。
10~20分程度で終わりますが、使用しているPCのスペックやネット環境によっては1時間ほどかかる場合も。
2回目以降は1分程度で起動できるようになるので、初回だけは気長に待ちましょう。
Stable Diffusionのアップデートが公開されると、まれにwebUIが起動できなくなる場合があります。
webui-user.batがエラーになったときは、webUIをアップデートしてから再度実行してみてください。
アップデートしたいときは、webuiフォルダ内で右クリックメニューから「Git BASH Here」を選択します。
立ち上がったコンソールに「git pull」と入力してエンターキーを押し、$マークだけの行が表示されるまで待ちましょう。
処理が終わればアップデート完了です。
必要なモデルデータを手に入れる
webUIには標準のモデルデータも同梱されていますが、別のモデルを利用したい場合は配布サイトなどで入手できます。
以下のようなサイトでモデルデータを入手しましょう。
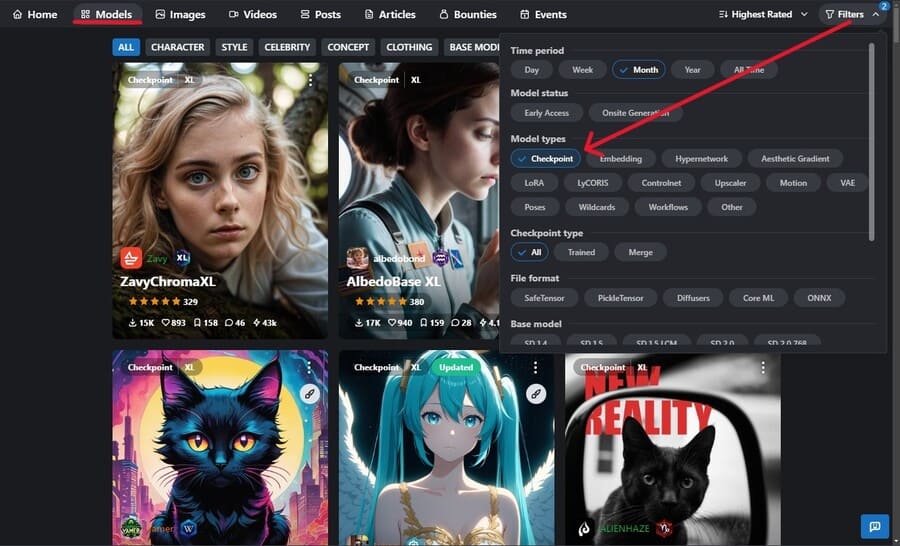
とくにCivitaiは、生成できる絵の例が見やすくて便利です。

「Models」タブを選択し、FiltersでModel Typesを「Checkpoint」に絞って、気になるモデルデータを探しましょう。
欲しいモデルデータを見つけたら、詳細画面の右上にある「Download」ボタンからダウンロードします。
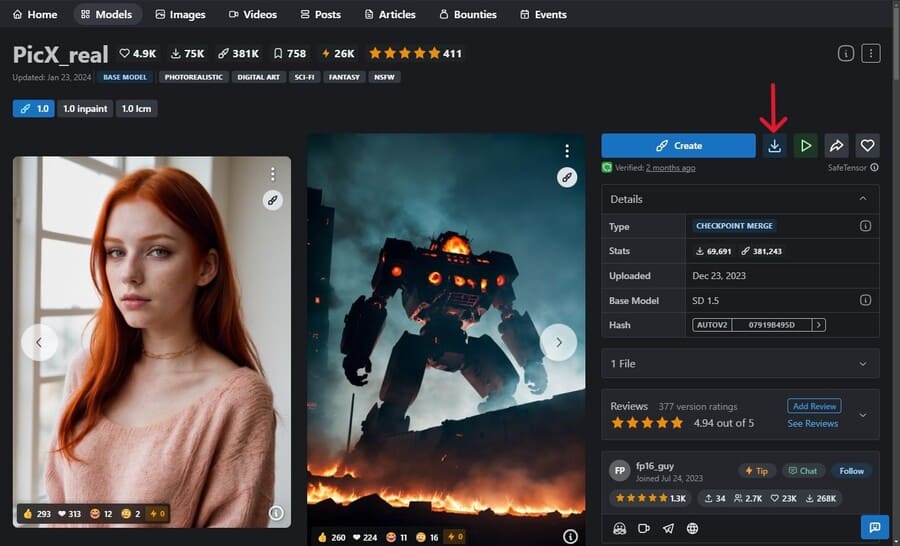
ダウンロードしたモデルデータのファイルは、下記の場所に置いてください。
- webuiフォルダ\models\Stable-diffusion
ファイルを置いてからwebUIを起動すれば、画面上部でモデルデータを選択できるようになります。

すでにwebUIを起動している状態でモデルを配置したときは、右にある矢印アイコン(🔄)をクリックしましょう。
safetensorsファイルとckptファイルの違い
モデルデータによっては、拡張子(ファイル名の末尾)がsafetensorsとckptの両方が配布されています。
この場合は、必ずsafetensorsをダウンロードしてください。
なぜならsafetensorsは、ckptにセキュリティ性を追加した、上位のファイル形式だからです。
| 比較点 | safetensors | ckpt |
| 悪意あるコードを実行する可能性 | ない | ある |
| 画像を生成する速度 | 比較的速い | 比較的遅い |
ckpt形式だけで配布しているファイルには危険性があるので、不用意に利用しないよう注意しましょう。
Stable Diffusion webUIで利用できる機能と使い方

ローカル環境のwebUIでは、以下の機能が利用できます。
- txt2img:プロンプトから画像を生成
- img2img:画像をもとに新しい画像を生成
- Inpaint:画像の一部を修正
- PNG内の情報を表示:プロンプトを抽出
各機能の使い方を以下で解説するので、試しに触れてみるとよいでしょう。
ここから先は日本語化した前提で解説するため、以下の手順でツールを日本語表示にしましょう。
- 「Extenions」タブ内の「Available」タブで、「localization」のチェックを外してから「Load form:」ボタンを押す
- 表示される拡張機能から「ja_JP Localization」を探して「Install」ボタンを押す
- 「Settings」タブの左メニューで「User interface」を選択する
- 「Localization」の右にある矢印アイコンを押して「ja_JP」に変更する
- 上部にある「Apply settings」ボタンを押してから「Reload UI」ボタンを押す
ちなみに、「User interface」ではなく「Bilingual Localization」で設定を変更すれば、英語と日本語の両方を表示するバイリンガル機能を使えます。
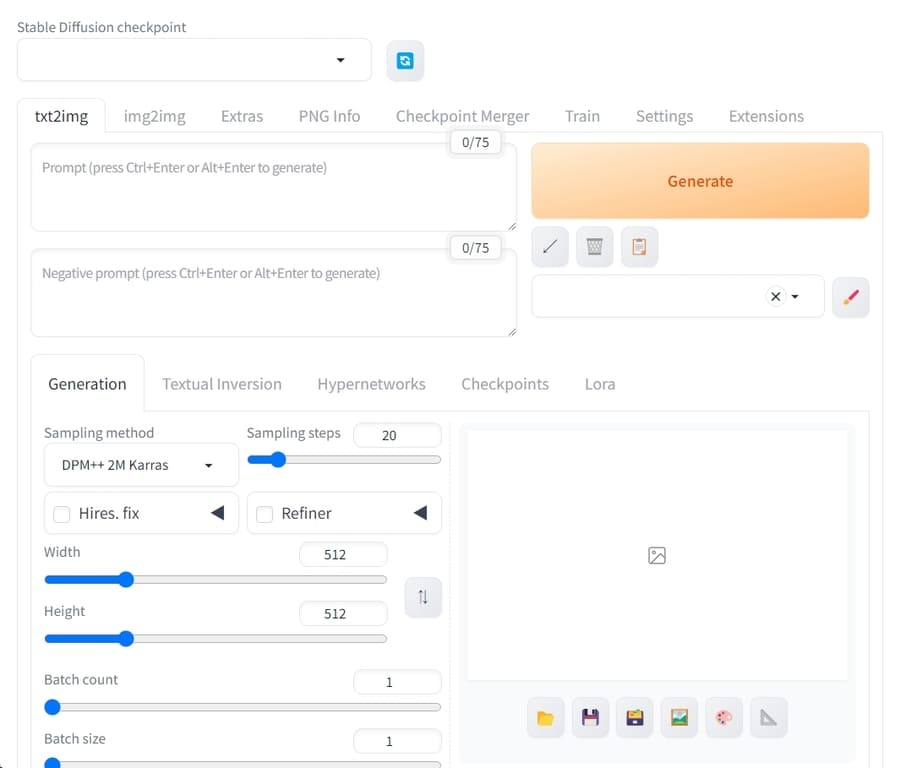
txt2img:プロンプトから画像を生成
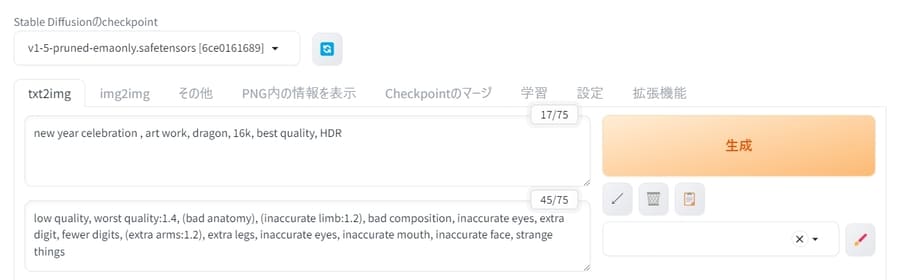
txt2imgタブでは、プロンプト(テキスト)から画像を生成できます。
使い方は、以下の項目を入力して「生成」ボタンを押すだけ。
- Stable Diffusionのcheckpoint・・・利用するモデルデータ
- プロンプト・・・生成したい画像の内容(英語で入力)
- ネガティブプロンプト・・・画像に含めたくない内容(英語で入力)
その他の設定項目の概要は以下のとおり。
| 項目 | 概要 |
|---|---|
| サンプリング方法 | 生成時に使用するサンプラー(サンプリングアルゴリズム)。 サンプラーによって、生成速度や画風が異なる。DPM++ SDE KarrasやDPM++ 2M Karrasが人気。 |
| サンプリングステップ数 | サンプリングする回数。 多いほど高品質になりやすく、時間がかかる。 |
| 高解像度補助 | 生成した画像を拡大+高解像度化してから出力する。 拡大率なども設定可能。 |
| Refiner | SDXL使用時にRefinerとして利用するモデルデータを選択する。 |
| 幅、高さ | 出力する画像のサイズ。512×512のサイズでモデルデータを学習している場合が多いため、変えないほうが良い結果になりやすい。 |
| バッチ回数 | 画像生成の処理を並列しておこなう数。 負荷が大きいため、1にするのが無難。 |
| バッチサイズ | 生成する画像の枚数。 同じ設定でくりかえしボタンを押す手間が省ける。 |
| CFGスケール | プロンプトを適用させる度合い。 数値が大きいとプロンプトに沿った画像になりやすい。 数値が小さいと画像が破綻しにくい。 |
| シード | 画像生成のもととなる数値。ほかの設定が同じ場合、シードの値を固定すれば同じ画像を生成する。 -1にすると、ランダムな値で画像を生成できる。 |
画像の下にあるボタンを押せば、他の機能へ生成した画像を直接転送することが可能です。

画像の保存場所
設定を変更していなければ、生成した画像はすべて自動的に保存されます。webuiフォルダ内のoutputsで機能別に分けられているので、チェックしてみましょう。
webUIの画像表示部分の下にあるフォルダアイコンのボタンを押せば、保存しているフォルダを開けます。
もし自動的に保存したくなければ、「設定」タブ内の「画像/グリッド画像の保存」で、「生成された画像をすべて保存する」のチェックを外してください。
img2img:画像をもとに新しい画像を生成
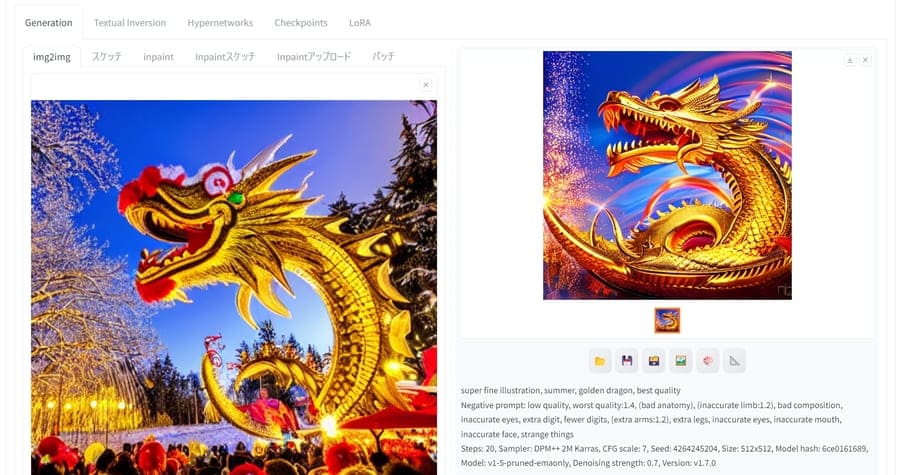
アップロードした参照画像とプロンプトをもとに、新しい画像を生成します。すでに生成した画像と似た構図にしたいときに利用するとよいでしょう。
ほとんどの設定項目はtxt2imgと同様ですが、以下のような項目が追加されています。
| 項目 | 概要 |
|---|---|
| ここに画像をドロップ – または – クリックしてアップロード | 参照する画像。 |
| サイズ変更の方式 | 参照画像と生成画像の大きさが異なる際に画像サイズを変更する方法。 |
| ノイズ除去強度 | 参照画像が影響する度合い。数値が大きいほど参照画像の影響が薄まり、プロンプトが影響しやすくなる。 |
サイズ変更の方式で選べる選択肢による違いは、以下のとおりです。
- 変形:縦横比を無視して画像を引き伸ばしたり縮めたりする
- 縦横比を維持(切り取り):縦横比を維持したまま拡大・縮小してはみ出る部分を切り取る
- 縦横比を維持(埋める):縦横比を維持したまま拡大・縮小して足りない部分を補完する
- 変形(latent アップスケール):変形したうえで高画質化処理をする
Inpaint:画像の一部を修正
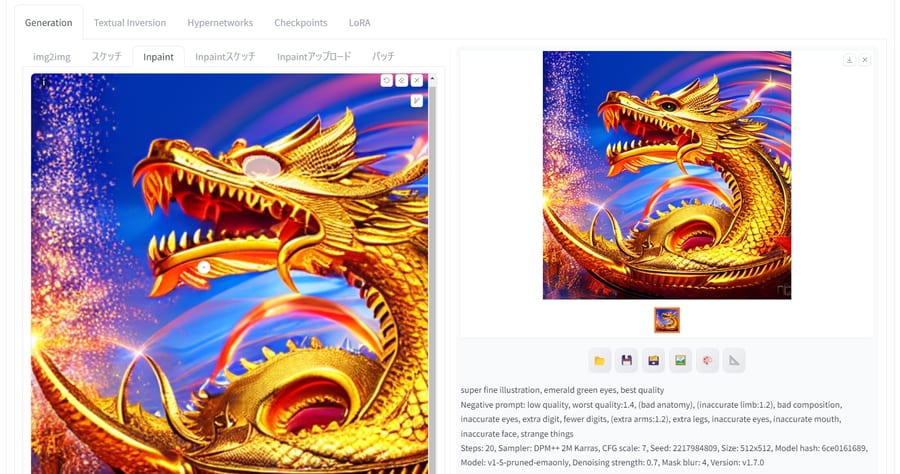
画像の一部だけ変更したい場合はInpaint機能を使います。
Inpaint機能を使えば、人物の服装を変更したり、背景の一部を消去したりできます。img2imgの画像アップロード箇所の上にある「Inpaint」タブを選択してください。
参照画像をマウスで直接ドラッグ操作すれば、画像生成時に変更されるマスク部分を指定できます。

マスク部分が周りと馴染まないときは「マスクのぼかし」の数値を調整してみるとよいでしょう。
PNG内の情報を表示:プロンプトを抽出
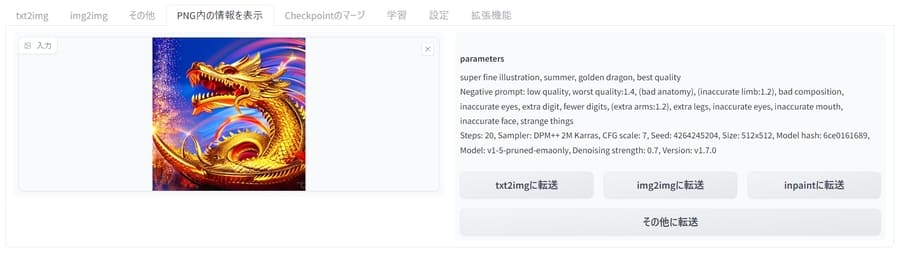
画像をアップロードすると、生成時に使われたプロンプトや設定が抽出され、画面に表示されます。
過去に生成された画像のプロンプトを参考にしたいときに重宝するでしょう。
ただし、生成後にペイントツールなどで編集・保存した画像からは抽出できないので注意してください。
Stable Diffusionに関するQ&A
Stable Diffusionに関する、よくある質問と回答を紹介します。
- プロンプトに何を書けばいいか分かりません
- プロンプトを書くコツを教えてください
- Stable Diffusion XL(SDXL)とは?違いはある?
- VAEファイルとは何ですか?
- LoRAとは何ですか?使い方は?
- 画像から動画を生成することはできますか?
- 商用利用や著作権に関する問題はありますか?
- サーバーに構築した環境を他ユーザーに提供・共有できる?
- プロンプトに何を書けばいいか分かりません
-
以下にプロンプトの一覧を掲載した記事があるので、こちらを参考にしてアイデアを膨らませてみましょう。
あわせて読みたい Stable Diffusionで服装を指定するプロンプト(呪文)例を一覧で紹介 Stable Diffusionで人物を描く際、服装を指定することは重要です。 しかし、 服装をどのように指定すればいいのかわからない 服装のバリエーションを増やしたい 一風変…あわせて読みたいStable Diffusionの髪型・髪色に関するプロンプト(呪文)例を一覧紹介 Stable Diffusionで魅力的なイラストを生成するには、髪型を指定するプロンプトが重要です。 しかし、 髪型を指定するプロンプトの書き方がわからない 髪色や髪質に関す…あわせて読みたいStable Diffusionの表情に関連したプロンプト(呪文)一覧 Stable Diffusionのプロンプトで表情を指定しないと、画像を生成するたびに表情がコロコロと変わってしまいます。 笑顔や怒り顔、驚きといった表情や感情を指示するのは…あわせて読みたいStable Diffusionで背景・風景を生成するプロンプト(呪文)一覧 画像の背景は、見る人にシチュエーションを伝えるための大切な要素の一つです。 Stable Diffusionで画像を作る際に、狙い通りの背景を生成したいと誰もが考えるはず。 …
Stable Diffusionで服装を指定するプロンプト(呪文)例を一覧で紹介 Stable Diffusionで人物を描く際、服装を指定することは重要です。 しかし、 服装をどのように指定すればいいのかわからない 服装のバリエーションを増やしたい 一風変…あわせて読みたいStable Diffusionの髪型・髪色に関するプロンプト(呪文)例を一覧紹介 Stable Diffusionで魅力的なイラストを生成するには、髪型を指定するプロンプトが重要です。 しかし、 髪型を指定するプロンプトの書き方がわからない 髪色や髪質に関す…あわせて読みたいStable Diffusionの表情に関連したプロンプト(呪文)一覧 Stable Diffusionのプロンプトで表情を指定しないと、画像を生成するたびに表情がコロコロと変わってしまいます。 笑顔や怒り顔、驚きといった表情や感情を指示するのは…あわせて読みたいStable Diffusionで背景・風景を生成するプロンプト(呪文)一覧 画像の背景は、見る人にシチュエーションを伝えるための大切な要素の一つです。 Stable Diffusionで画像を作る際に、狙い通りの背景を生成したいと誰もが考えるはず。 … - プロンプトを書くコツを教えてください
-
以下のポイントを意識してプロンプトを入力すると、良い結果を得やすくなるでしょう。
- カンマ(,)で区切って複数の単語を書く
- 重視したい内容を先に入力する
- ネガティブプロンプトも入力する(low quality、extra digitなど)
- プロンプトを長くしすぎない
- 重さ付け(優先度)を設定する ※記入例:(smile:1.5)
書き方がいまひとつ分からないのであれば、ほかの人が生成した画像のプロンプトを参考にしてみてください。
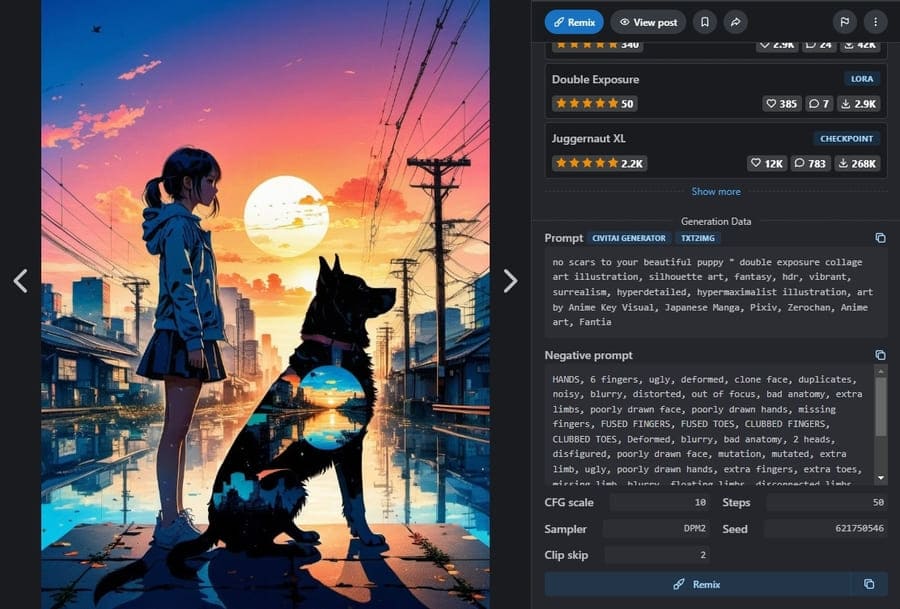
たとえば、Civitaiの「Images」タブで閲覧できる画像は、詳細ページでプロンプトを確認・コピーできますよ。
出典:Civitai 生成画像に表示させたくない要素をしていするネガティブプロンプトのまとめについて、以下の記事で紹介しているので参考にしてください。
あわせて読みたいStable Diffusionのネガティブプロンプト一覧!使い方やおすすめも解説 Stable Diffusionで高品質な画像を生成するには、プロンプト(AIへの指示文)だけでなく、ネガティブプロンプトも活用する必要があります。 ネガティブプロンプトとは?… - Stable Diffusion XL(SDXL)とは?違いはある?
-
SDXLは、2023年7月に公開されたStable Diffusionのアップグレード版です。
BaseとRefinerという2種類のモデルデータで処理することにより、より高画質かつ鮮明な画像を生成できます。
標準のSDXLを利用する際は、以下のデータを指定の場所に置いてください。
ダウンロードするデータ 配布しているページ 置く場所 sd_xl_base_1.0.safetensors
(必須)https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main webuiフォルダ\models\Stable-diffusion sd_xl_refiner_1.0.safetensors https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/tree/main sdxl_vae.safetensors https://huggingface.co/stabilityai/sdxl-vae/tree/main webuiフォルダ\models\VAE 画面上部のcheckpointでbaseデータを、設定中のRefiner内にあるcheckpointでrefinerデータを、それぞれ設定すればOKです。
SDXLのモデルデータは1024×1024の画像で学習しているため、生成する画像のサイズには注意しましょう。
SDXLについて詳しく解説している記事があるので、こちらも参考にしてください。
あわせて読みたいSDXL(Stable Diffusion XL)とは?旧モデルとの違いや使い方を解説 2023年7月、Stable Diffusionの後続モデルとしてSDXL(Stable Diffusion XL)がリリースされました。 しかし、 SDXLとStable Diffusionの違いがわからない SDXLを使う方…SDXLをベースにしたモデルデータの例として、Animagine XLなどが挙げられます。
あわせて読みたいAnimagine XLとは?アニメ系イラストに特化した画像生成AIモデルの使い方 Stable Diffusionで画像生成するときに使われる人気モデルの一つ、Animagine XL。 しかし、以下のような方も多いかもしれません。 そもそもAnimagine XLが何なのか知り… - VAEファイルとは何ですか?
-
VAE(Variational AutoEncoder)は、モデルデータの補助をする役割を持つデータです。
適したVAEを設定すれば、利用したファイルの特徴に応じて画質を向上させる効果があります。
VAEファイルはCivitaiなどで取得し、以下の場所に配置してください。
- webuiフォルダ\models\VAE
VAEを適用するには、webUIの「設定」タブの「Stable Diffusion」で「SD VAE」を変更します。
モデルデータと相性の悪いVAEを使うと逆効果になるため、VAEの有無を比較しながら試してみましょう。
- LoRAとは何ですか?使い方は?
-
LoRAとは、モデルデータとは別に追加できる学習データです。
LoRAファイルを使用すると、人物を特定のキャラクターにしたり、決まったシチュエーションにしたりできます。
使用するには、CivitaiなどでLoRAファイルをダウンロードし、以下の場所に配置してください。
- webuiフォルダ\models\Lora
使用する際は、以下のような文をプロンプトに入力しましょう。
- <lora:ファイル名:重さの数値>
- 画像から動画を生成することはできますか?
-
拡張機能AnimateDiffを導入すると、生成した画像をもとに動画を作れます。
ちなみに、Stable Diffusionを開発したStability AI社は、プロンプトから動画を生成するStable Video Diffusionもリリースしています。
動画の用途によっては、Stable Video Diffusionを利用した方がいいかもしれません。
あわせて読みたいStable Video Diffusionとは?使い方(ローカル環境も含む)や商用利用まで完全ガイド 2023年11月にStable Video Diffusionがリリースされて以来、動画を生成するAIツールが注目されるようになりました。 しかし、 Stable Video Diffusionがどんなツールな… - 商用利用や著作権に関する問題はありますか?
-
Stable Diffusionで生成した画像を商用利用する際は、以下の点に気を付ける必要があります。
- Stability AIのメンバーシップへの加入が必要な場合がある
- 利用するモデルによっては商用利用できない場合がある
- 著作権を侵害する画像が生成される可能性がある
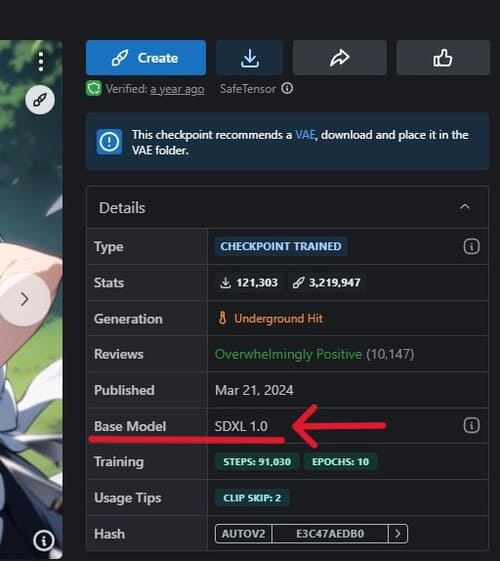
Core Modelsページに記載されているモデルを基にしたデータを商用利用する際はメンバーシップへの加入が必要なので、ベースモデルが何なのか必ずチェックしておきましょう。
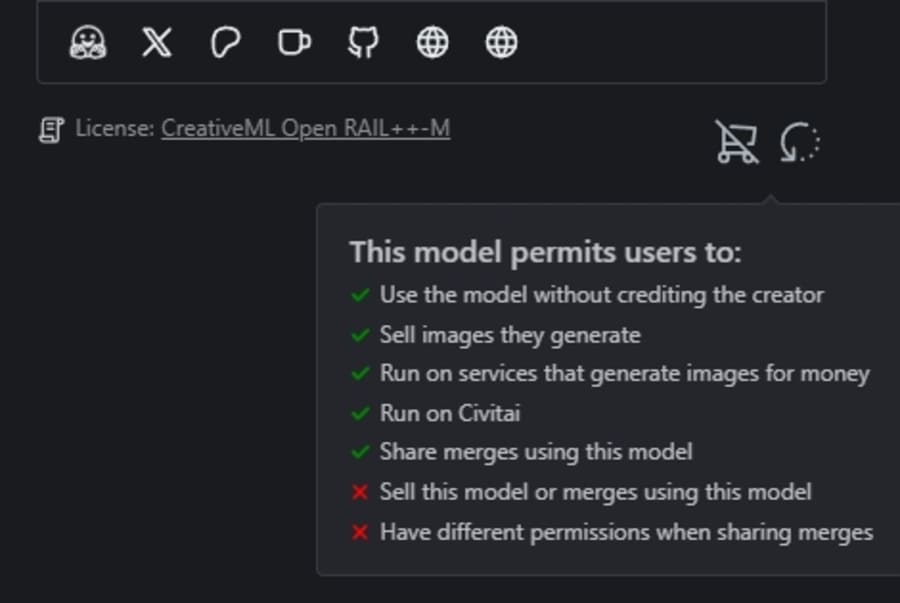
また、配布されているモデルごとに権利関係が異なる点にも注意してください。
Civitaiでモデルデータをダウンロードする場合は、詳細画面の右下で権利関係を確認できます。
さらに、生成結果によっては意図せず著作権を侵害する画像が出力される可能性も。
個人利用以外の目的で画像を生成する際は十分に注意しましょう。
- Stable Diffusion webUIを他ユーザーに提供・共有できる?
-
インターネットに接続されたサーバーに環境を構築することで、Stable Diffusion webUIを他のユーザーに提供したり共有したりできます。
自社サービスとして提供したい場合は、Stable Studioも利用すると良いでしょう。
あわせて読みたいStableStudioとは?オープンソース版DreamStudioで画像生成する方法を解説 当サイトはアフィリエイト広告を利用しています Stable Diffusionに関する情報を集めていると、StableStudioという言葉を耳にしたことがあるかもしれません。 しかし、…











まとめ
本記事では、Stable Diffusionについて解説しました。
最後に、記事の内容をおさらいしておきましょう。
- Stable Diffusionを使う方法は3通り
- 無料で簡単に使うならStable Diffusion Onlineなどのオンラインサービスを利用するとよい
- 大量に画像を生成したいのであればPCにローカル環境を構築するのがおすすめ
- ローカル環境の構築にはPythonとGitを利用する
- 変更する設定項目を少しずつ増やしながら慣れていき、思い通りの画像を生成できるようになろう
Stable Diffusionを使いこなせるようになれば、絵を描くスキルがなくても様々な画像を生成できるようになります。
自分に合った方法でStable Diffusionを利用し、試行錯誤しながら最高の絵を作り上げましょう。
また、Stable Diffusion以外の画像生成ツールに興味があれば、別記事も読んでみてください。







